

Guides
Comprehensive Guide to the RAG Tech Stack
This guide walks through industry standard technology choices for building a RAG application. From vector databases to response evaluation tools, we cover different options per function category and our recommendations for starting your RAG tech stack.

Jack Mu
,
Developer Advocate
11
mins to read
Building a RAG application or feature for your SaaS product is an exciting exercise and tremendous product add. The good news is that there are a wide breadth of tools and frameworks to build RAG applications efficiently and of high quality. But with a wide breadth can come a paralyzing number of options.
This guide aims to help your team become more informed on what tools are out there. We encourage your team to read the documentation of tools you’re interested in, experiment, and begin building! There’s no substitute for hands-on experience. It’s the best way to learn these tools deeper and how to evaluate options even better in the future.
With that said, this guide will cover the following:
The tech stack you need to achieve the most basic RAG functionality
Framework options to help your team build faster and with structure
The tools that will help your team optimize performance and get to production
Short Summary (TLDR)
For building your RAG application, the most basic functionality can be implemented with an LLM, embedding model, and vector database.
For these, we recommend an OpenAI tech stack:

LLM: GPT-4o for its general usefulness and familiarity
Embedding Model: text-embedding-large-3
Vector Database: Pinecone for its managed, cloud-native solution that’s easy to onboard and try out
LLM Frameworks can bring useful interfaces that reduce the amount of custom code you need to bring more reliability and faster development times in using the above technologies. We recommend LlamaIndex for its emphasis on performant retrieval and ease in onboarding:

To bring a RAG application from POC to production, these technologies greatly aid in monitoring, security, testing/evaluation, and native integrations:

Monitoring: OpenLLMetry for OpenTelemetry style tracing that integrates with products like Splunk and Datadog
Security: LLMGuard for detecting prompt injections and jailbreaking
Security: Okta FGA for ReBAC-based data authorization of retrieved documents
Testing/Evaluation: Uptrain for evaluation metrics like response quality, hallucinations, and security risk; Uptrain also has a self-hosted dashboard to monitor LLMOps
Integrations: Paragon for scaling native integrations used for extracting your users’ 3rd-party data to your application backend
Please read the full article for alternative technology choices per category in a RAG tech stack, and how we reached these recommendations.
Tech stack for basic functionality
This section will focus on tools you will absolutely need (unless you’re planning on building your LLM and embedding model from scratch, which if that’s the case, good luck!). These tools are your:
LLM
Embedding model
Vector datbase
LLM
There are many LLMs on the market, provided by some of the biggest tech companies and a growing number of AI-focused companies. A non-exhaustive list include:
While it can be hard to evaluate between LLMs, a first step is to look at the features and strengths these LLMs market themselves to in their release announcements and documentation. For example, just looking at OpenAI’s LLMs:
gpt-4o is multimodal, meaning different forms of inputs including images can be used
the gpt-4 is known for it’s breadth
gpt-4o-mini optimizes for smaller tasks
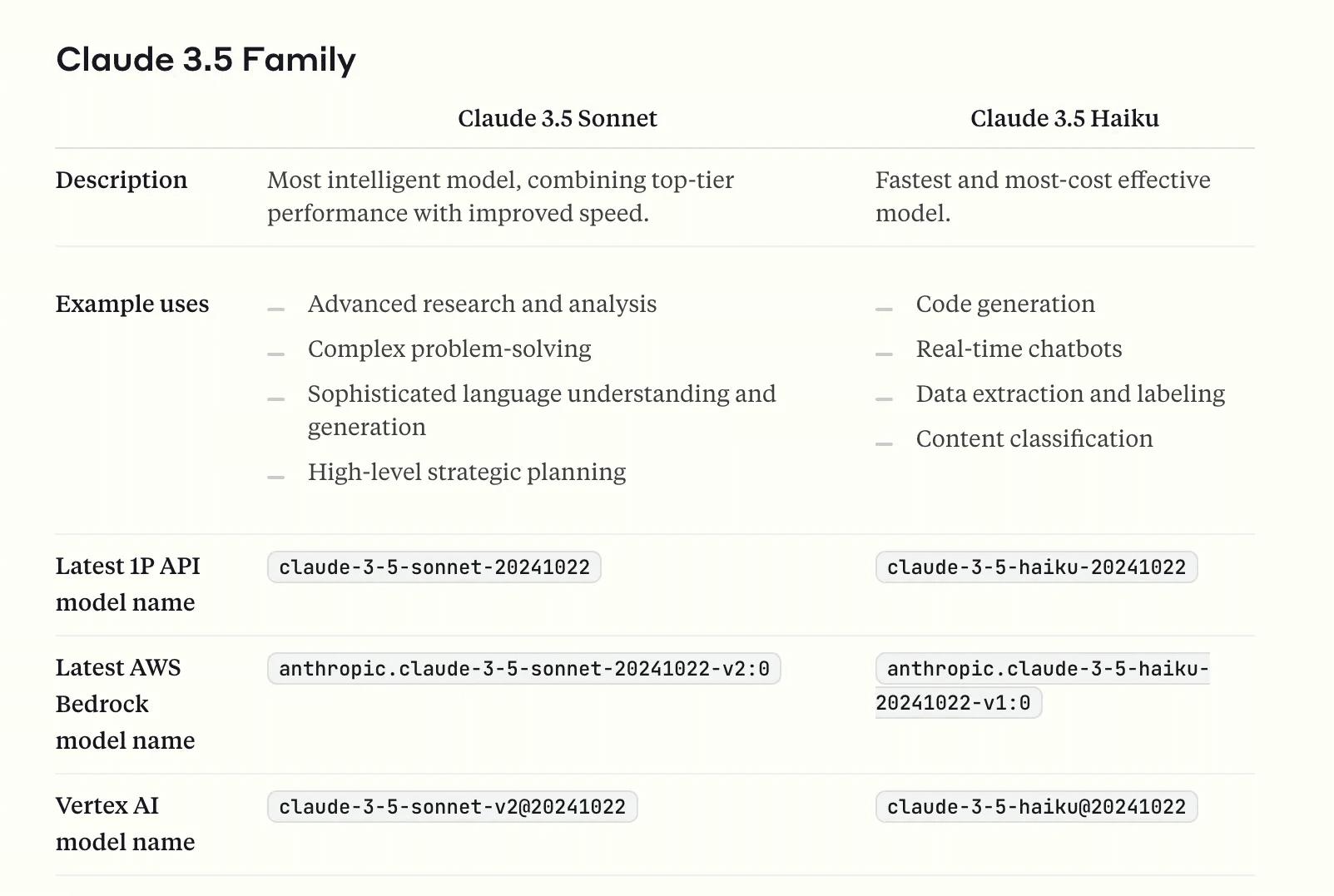
Each LLM will also have documentation on context window sizes, output sizes, specific use cases and pricing. I personally find going into the developer docs for each LLM provider as the best way to get information on the LLM before trying it hands-on. Another example using Anthropic this time:
Claude 3.5 Haiku boasts better code generation and ability to label and classify
If your RAG use case is one that needs those functionalities vs a more general knowledge and reasoning, your team should evaluate Claude Haiku over Sonnet and Opus
One last note, if your RAG application requires different types of use cases, it may be worthwhile to utilize multiple LLMs and use an intermediary LLM or model to classify the task before assigning an LLM to use.
Embedding model
Embedding models are how text is transformed into vector embeddings - essential to the RAG process as they are used to search for similarity searches to retrieve relevant external documents. These models vary in number of dimensions they support, token sizes, latency, and use cases.
Huggingface’s MTEB leaderboard is a great place to start, as you can evaluate the above specifications while filtering by use case (i.e. classification, re-ranking, summarization, etc).
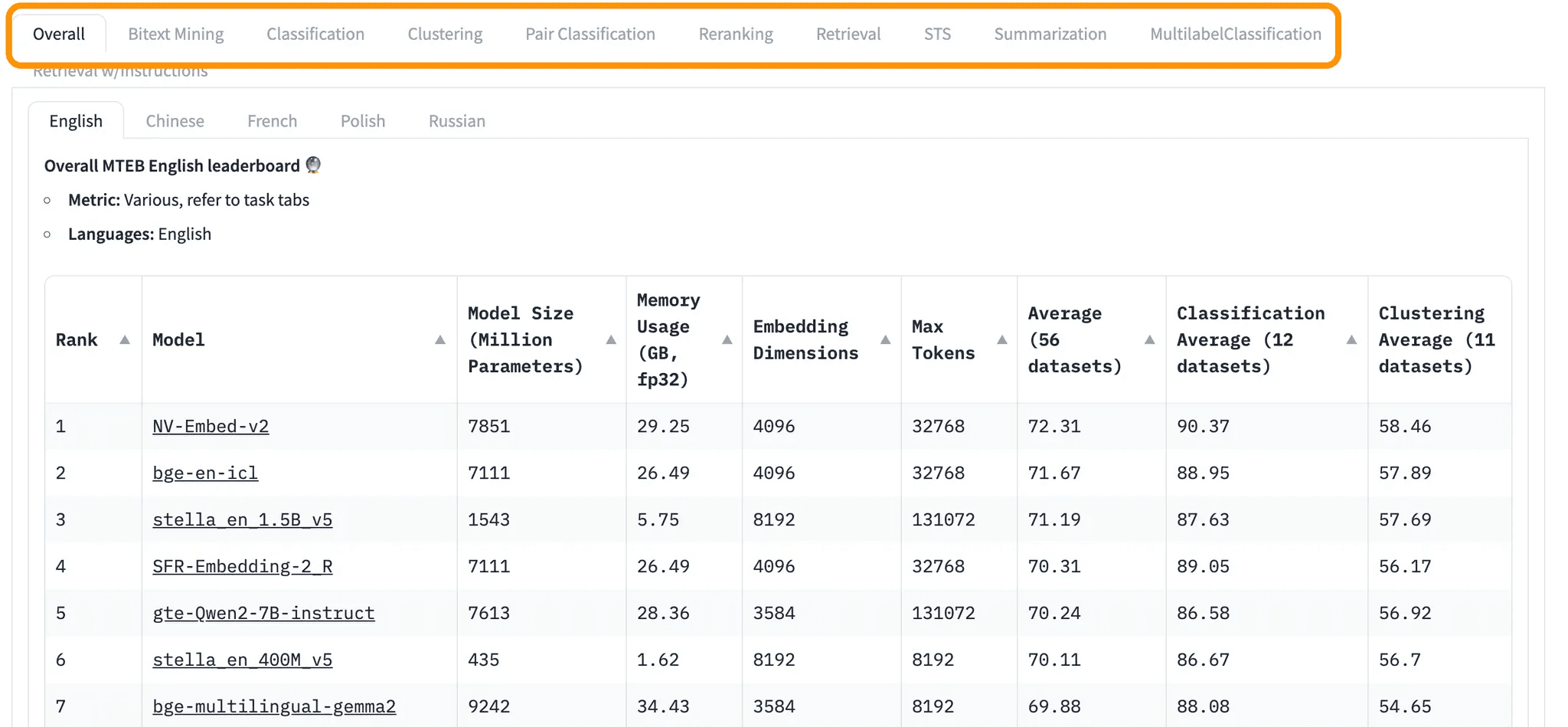
Embedding model will directly affect retrieval as RAG involves embedding a user query and searching for similar vectors from your external document knowledge base. This brings us to vector databases for storage and search.
Vector database
As mentioned, vector databases are optimized for storing and retrieving vectors. After your RAG application uses an embedding model to transform text into vectors, your application will use a similarity metric like cosine distance to return vectors with their corresponding text for your LLM to use.
Vector databases primarily fall under 2 main categories:
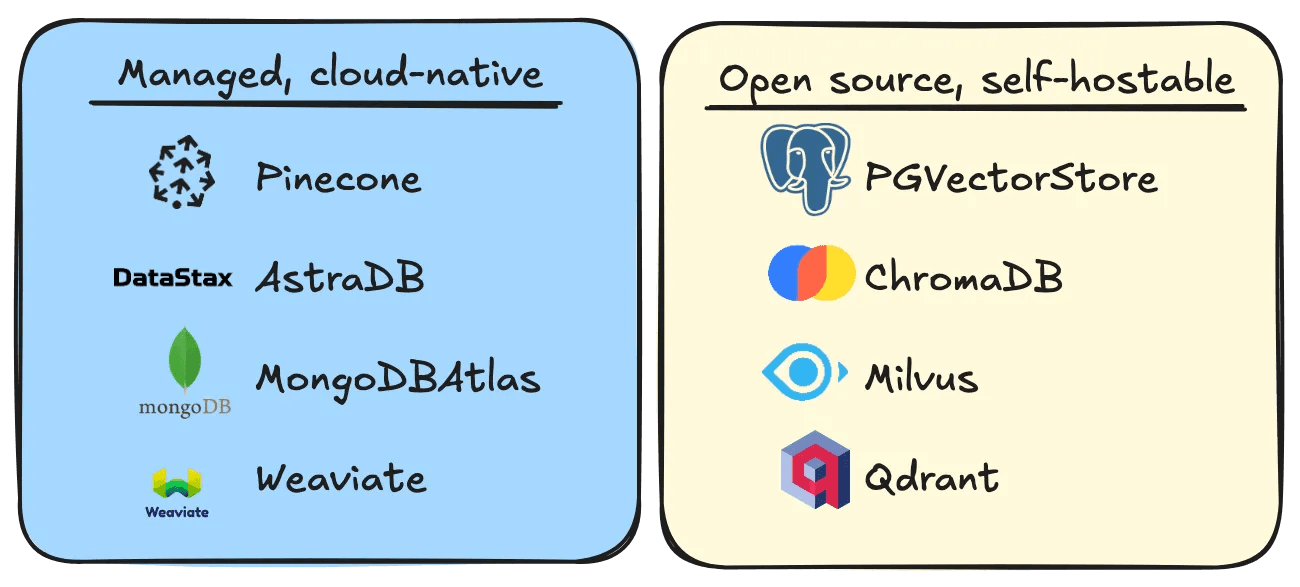
Vector databases should also be evaluated on their filtering features, client SDK, and native integrations with LLM frameworks (we’ll go into that below).
Our recommendations for the basic tech stack
The LLM, embedding model, and vector database make up the backbone of a RAG application. For the most bare-bones implementation, this tech stack is technically all you need.
If you’re just starting to poc or play around with RAG, a good place to start would be to use OpenAI tech stack: gpt-4o, text-embedding-3-large, with a pinecone database.
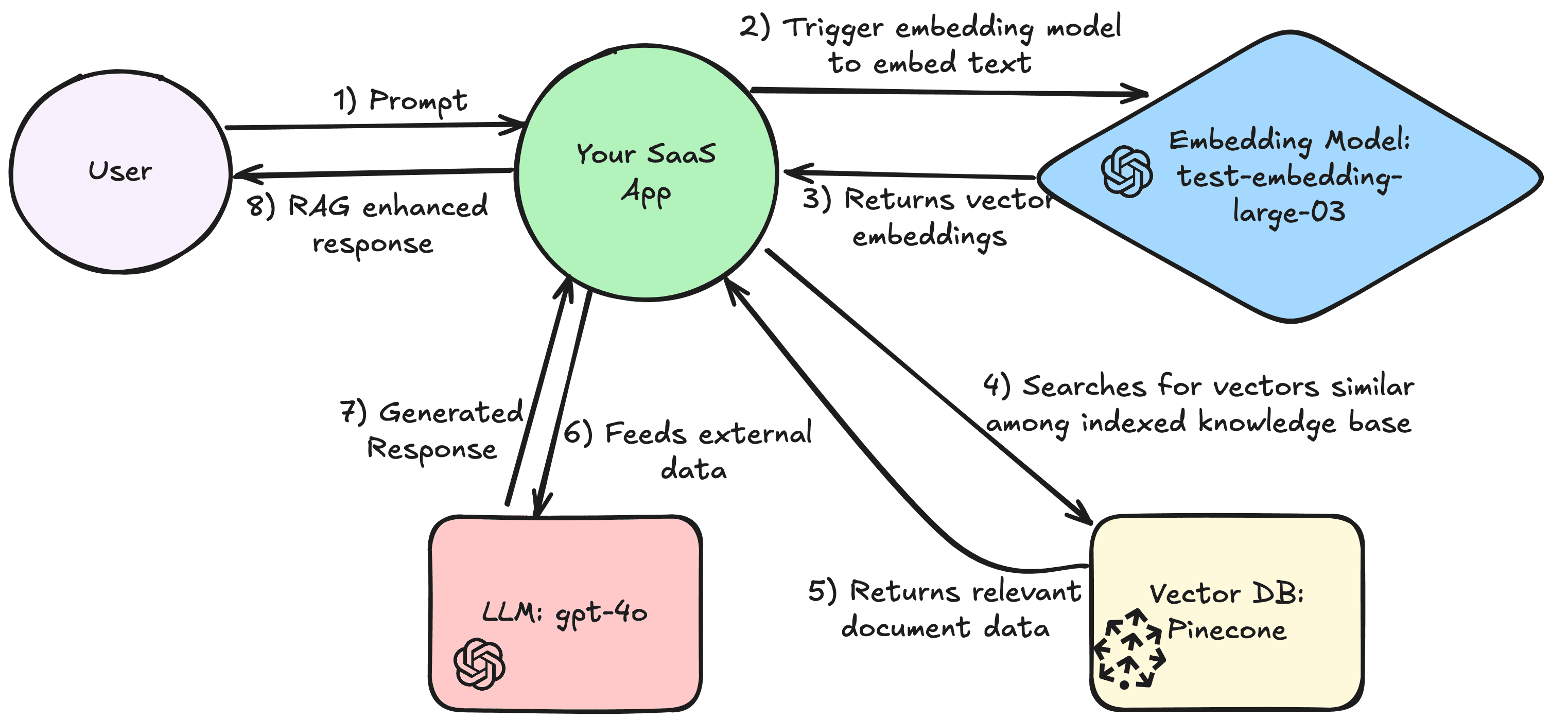
We recommend this because OpenAI’s gpt-4o is a good general purpose language model, you probably already have familiarity with OpenAI and GPT, and Pinecone is a fully managed database with an easy-to-start process (also has a free pricing model up to a storage limit).
Now that we have the basics, let’s discuss using an LLM framework to better structure your project and speed up development.
LLM Framework
LLM Frameworks are libraries that provide abstractions and interfaces for RAG and AI applications. These include interfaces for vector stores, retrievers, chat interactions, and function tools.
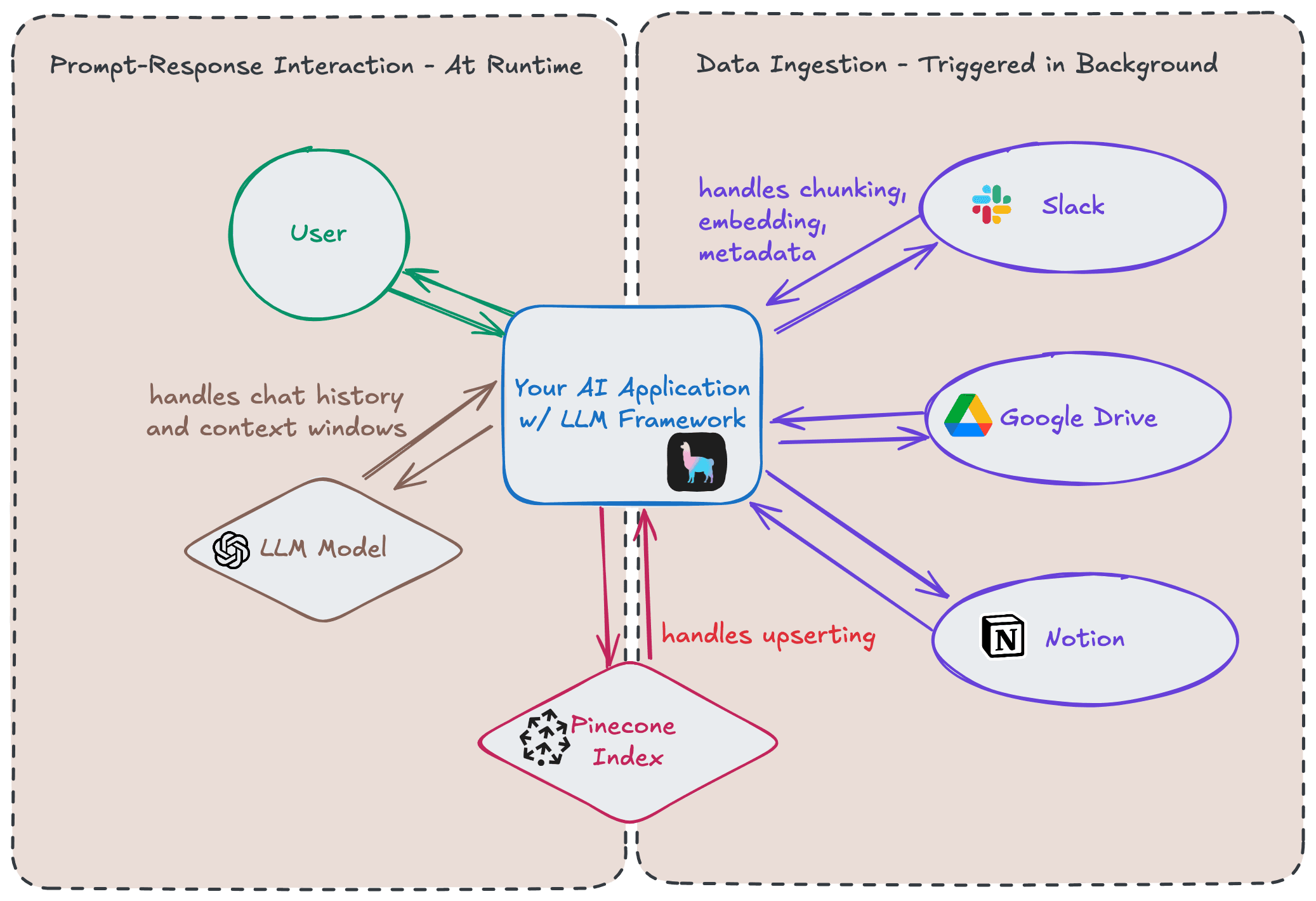
Benefits
Abstractions
Take for example, when indexing large documents like a 50 page PDF, we want to “chunk” the document into small pieces for better retrieval and to accommodate embedding model limits. Rather than build out custom logic that splits text into a token window, LlamaIndex’s library will have built out objects (IngestionPipeline, SimpleNodeParser).
Interchangeable stack
Another benefit of these interfaces is that they reduce code refactors when evaluating tech stack options that are integrated with these frameworks. Imagine your team is evaluating Pinecone and AstraDB for your vector store. Because these vector databases fall in the VectorStore interface, your developer team can quickly swap vector databases while keeping code refactors relatively small.
Framework options
The most popular LLM frameworks are LangChain and LlamaIndex. Both provide modules that abstracts common RAG processes like indexing, retrieval, and workflows. LangChain’s strengths are its flexibility in supporting different use cases, agent interactions, and integrations. LlamaIndex focuses on efficient and performant retrieval with a strong emphasis on parsing and indexing text for better response context.
Other frameworks like NeMo Guardrails and Haystack offer more specific use cases like being more strict on safety (Guardrails) and marketing themselves as more production-ready (HayStack)
Potential downsides
Like any framework, there are potential downsides associated with relying on pre-built abstractions.
These abstractions can be limiting depending on your use case
Your team could become reliant on the framework maintainers to implement functionality and fix bugs
The framework of choice may not have native integrations with the tech stack you’re using
The frameworks out there have the most support for python, with slightly less support for node.js, and pretty much no support for other languages
Frameworks are inherently opinionated so do research into the documentation and implementation to make sure the framework's opinionated way of abstracting LLM application details fits your use case.
Our recommendation for LLM framework
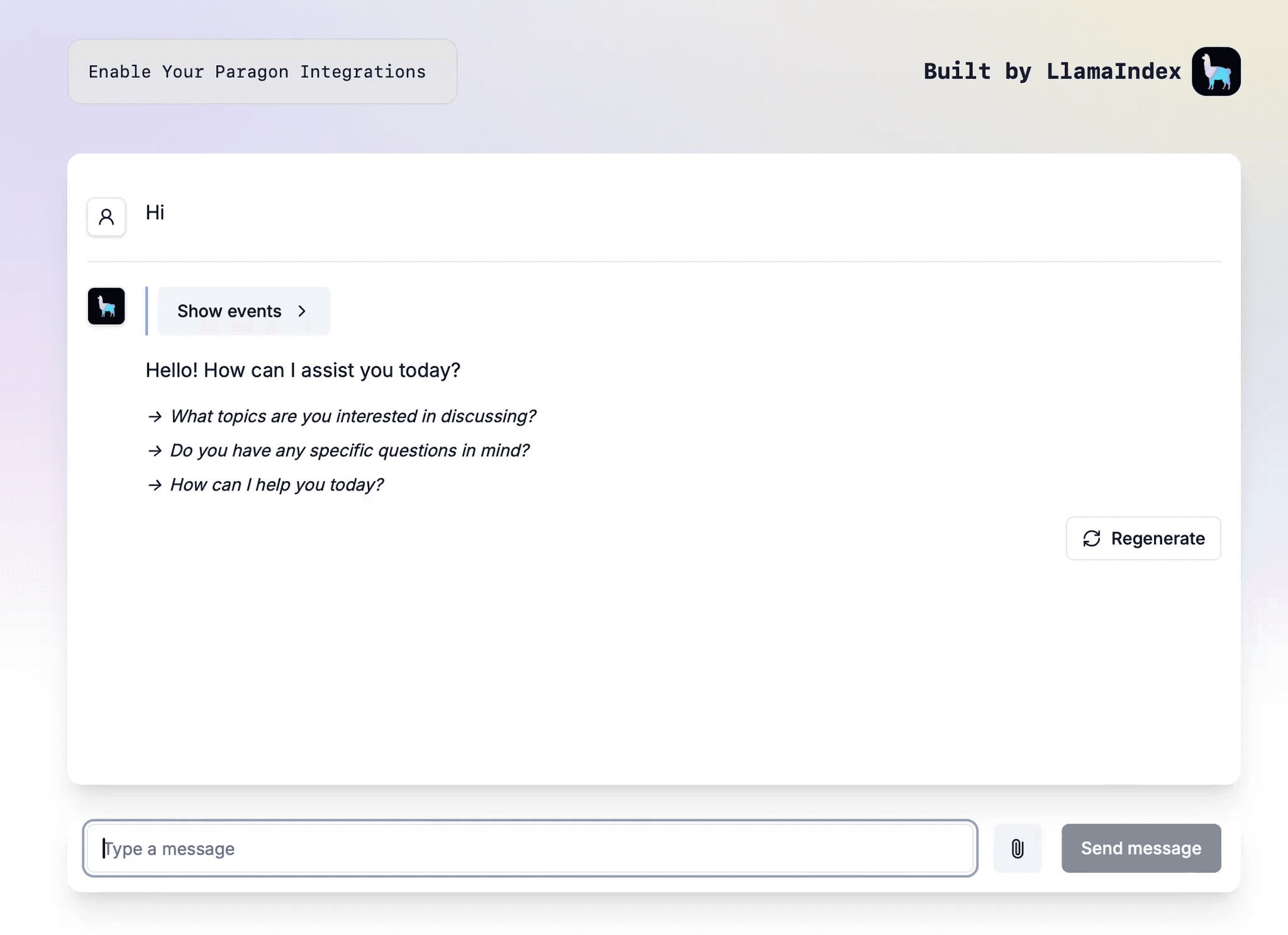
We recommend using LlamaIndex as a starting framework. Our team has tried out LlamaIndex ourselves to build RAG applications. They even have a handy npm CLI tool create-llama to spin up starter code that gets you on your way to testing RAG functionality in a few hours. The starter code even offers an aesthetic frontend in Nextjs. Here's a screenshot from an integration-enabled RAG tutorial we built out using create-llama.
From our experience, we see that most AI tools and libraries prioritize SDKs and clients written in python, so we would also recommend using a python framework like FastAPI, Flask, or Django if you have the ability to decide/change your programming language. Node.js and typescript (what we use) is also fairly well supported.
With this section on LLM frameworks complete, our last section will describe technology choices relevant for bringing your RAG application to production.
Tech stack for optimization and production
With a framework on top of your LLM, embedding model, and vector database, it can be surprisingly fast and easy to spin up a POC with RAG capabilities. This last section focuses on technologies that bring your POC application closer to production-ready with monitoring, security, testing, evaluation, and integrations in mind.
Monitoring
Like a non-RAG use case, applications in production should have tracing and logging. Traceloop’s OpenLLMetry is an open source solution that is built on top of OpenTelemetry. This means you can forward the tracing data from OpenLLMetry to any other system that collects Telemetry data like Splunk, Datadog, and NewRelic.
OpenLLMetry is also very easy to implement in your existing code base, taking advantage of wrappers and annotations to be able to trace specific workflows.
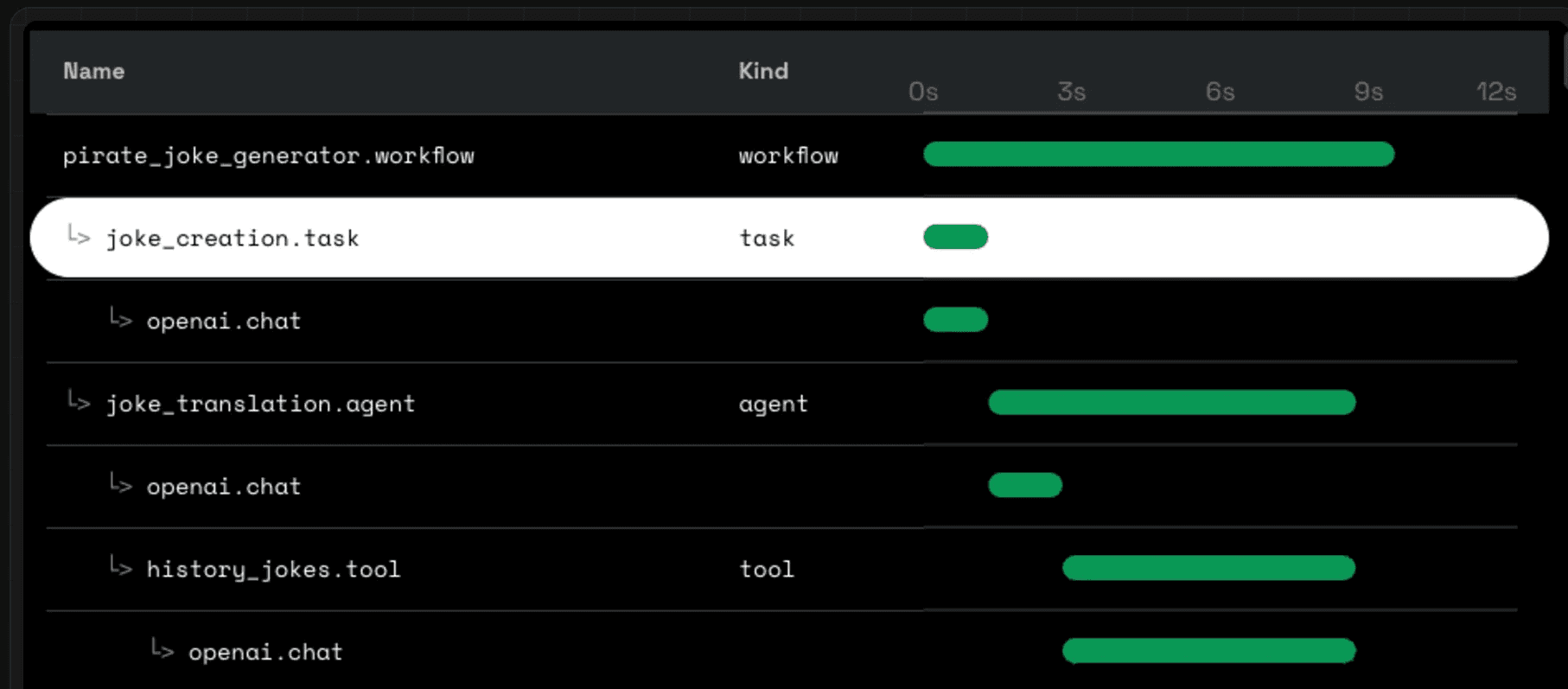
There are also vendors like Datadog and LangSmith that have built AI monitoring specific products with nice-to-have features like dashboards, graphical UI, and on-call support.
Security
RAG applications require a thought-out approach to malicious prompting and data authorization for contextual data.
In terms of malicious prompting, there are a few different approaches to combatting the security concern:
Libraries like LLMGuard and Guardrails AI help developer implement rules on user queries to guard against prompts using certain language like SQL injections
Intermediary security-focused LLM from LLMGuard, Guardrails AI, or Nvidia’s NeMo to sniff out malicious prompting
This diagram is from Nvidia depicting NeMo Guardrails where you have programmable guardrails (or rails) that check user inputs, LLM outputs, and RAG retrievals
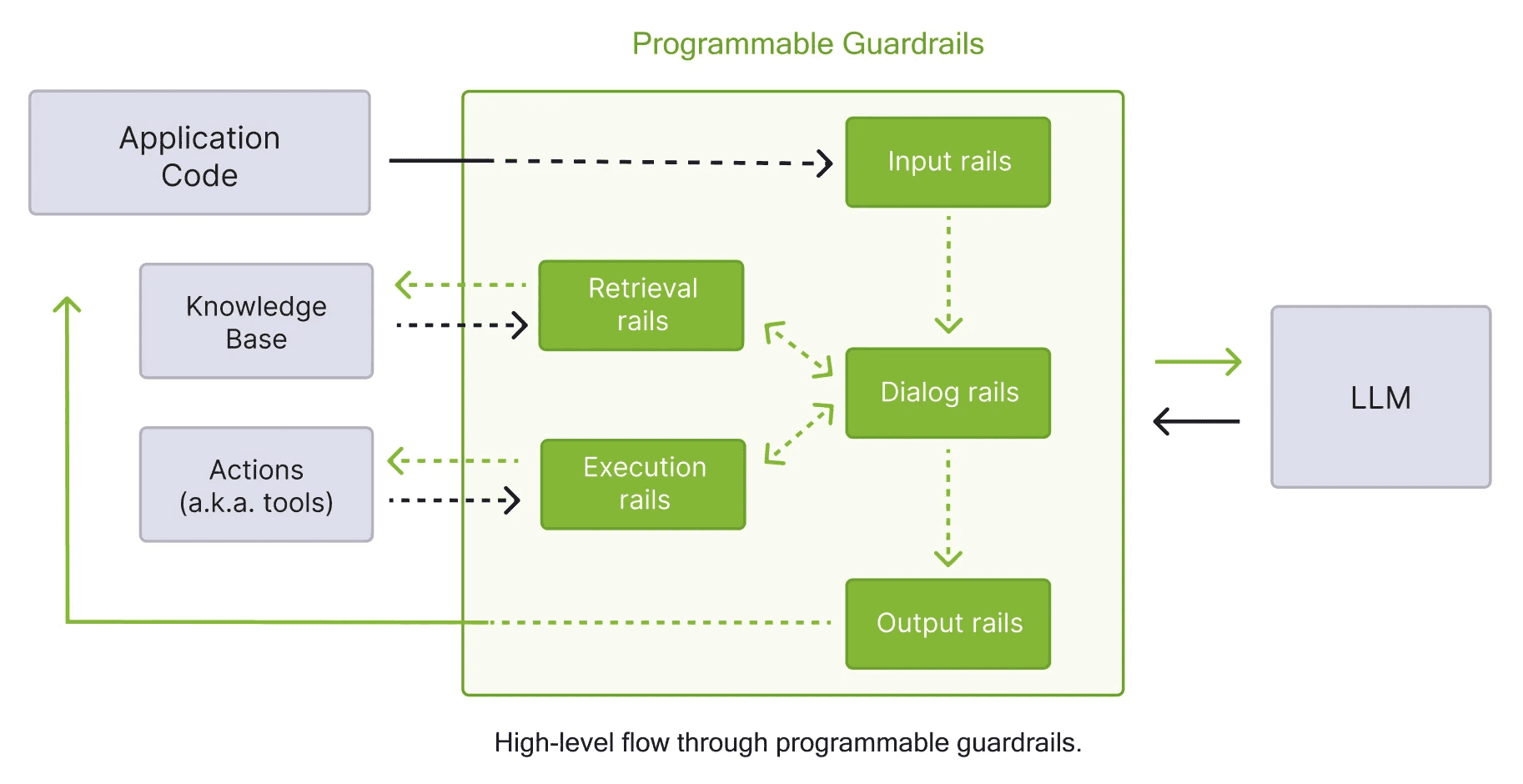
In terms of data authorization from vector retrieved documents:
Take advantage of “namespaces” in many vector database solutions to separate data from different tenants in your application
Example: Each enterprise customer has their own namespace and so they can only index and search for vectors in their namespace
Use a database from services like Okta’s Fine Grained Authorization for ReBAC (relationship based access control) to enforce permissions between users and documents and model all sorts of permissions relationships
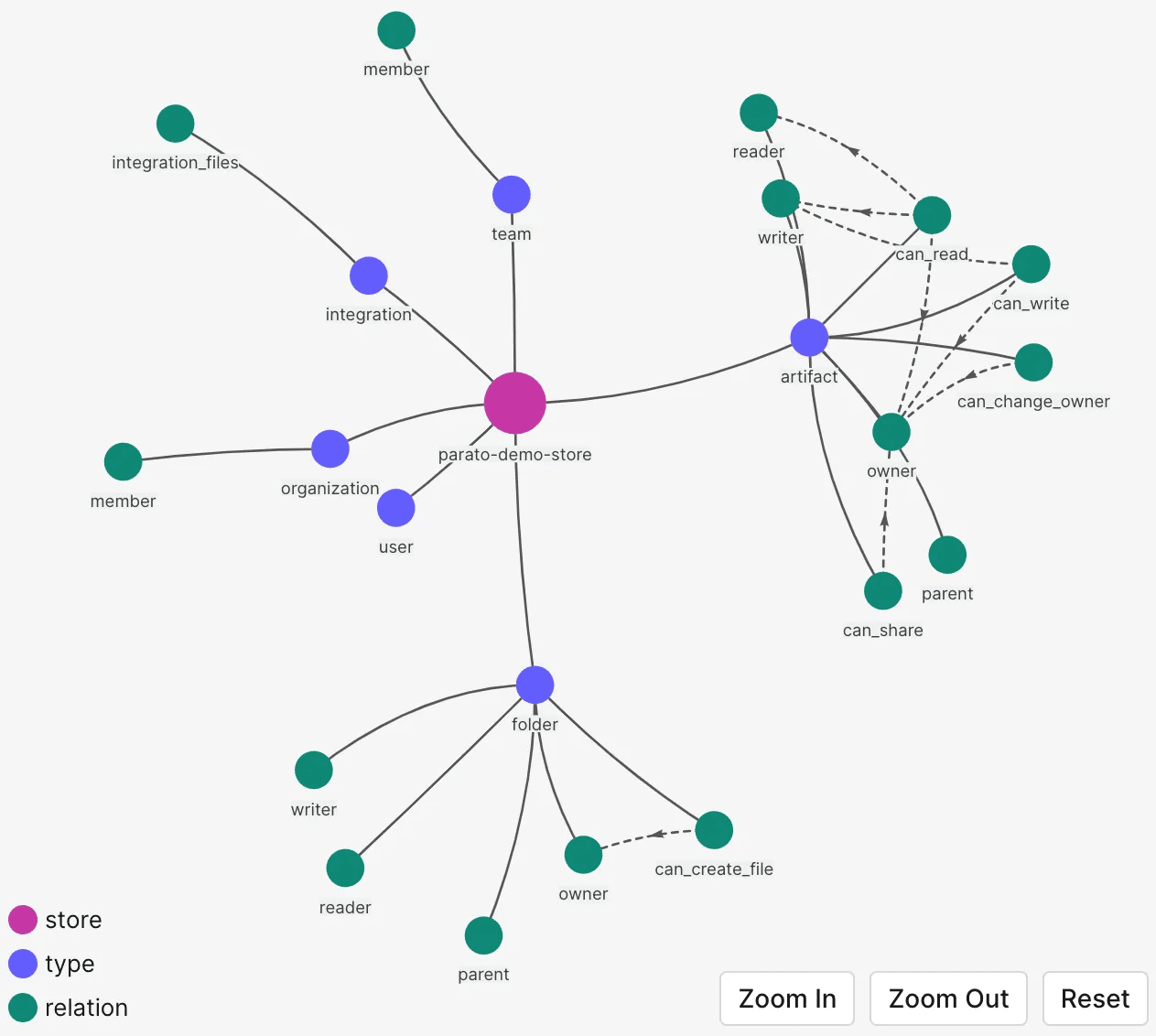
Other alternatives also work depending on your use case like RBAC (role-based) or an ACL kept in a relational database
Testing / Response quality evaluation
Evaluating response quality can be hard to do as it can be a very qualitative exercise. Evaluation methods can fall on the spectrum of qualitative to quantitative methods:

For the last method - the automated solution - there are frameworks that can:
Automate testing for specific prompts and expected response
Evaluate responses using metrics like faithfulness, relevancy, bias, hallucination, etc.
Test metrics while varying hyper-parameters like system prompts
Solutions that offer these functionalities are:
DeepEval: a python testing tool that supports 14 different metrics (like RAG context relevancy) where a specifically trained LLM judges responses for. they also have support for synthetic datasets simulating RAG processes.
Flowjudge: an open-source LLM for response evaluations. Their messaging is that their model is lightweight and efficient. They do not have an SDK or testing framework
Ragas: a different python-based testing tool with use-case specific metrics like metrics for SQL generation, tool use, and RAG context precision. They also have support for synthetic dataset generation.
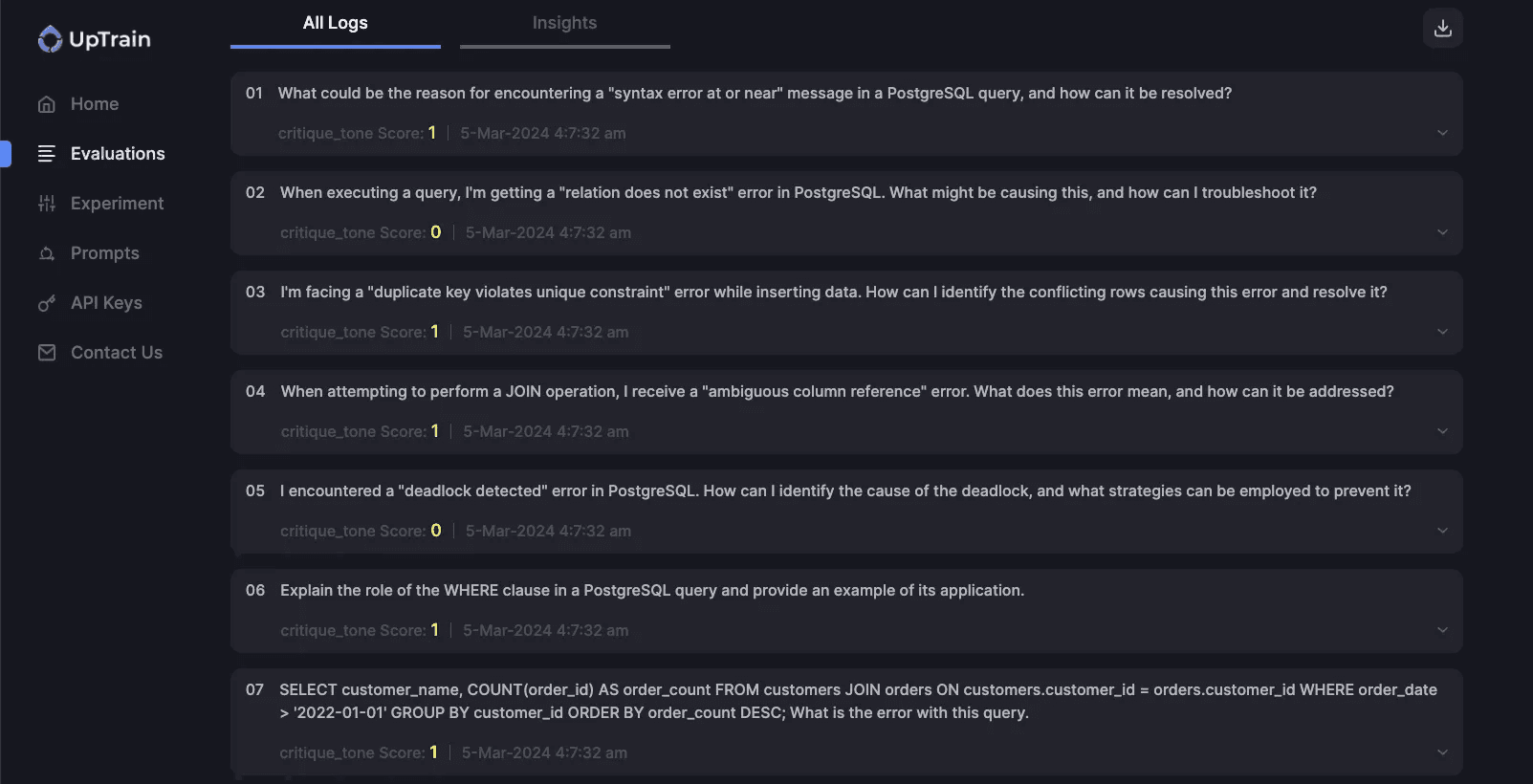
Uptrain: more of a platform with more RAG metrics, but also security metrics like prompt injection and jailbreaks. Uptrain also has a visual dashboard that can be spun up locally and become self-hosted.
Integrations
Integrations have become commonplace for SaaS applications in developing products that work seamlessly with your users’ other 3rd-party platforms. Embedded iPaaS (integration platform as a service) are products that help product and engineering teams implement integrations for users to connect their 3rd-party apps (like Salesforce, Google Drive, Slack) with your application. This is extremely useful for data ingestion - bringing your users’ data from Salesforce, from Google Drive, from Slack to your application for indexing to your vector database.
We have another article with a competitive analysis on other iPaaS products on the market, but (with a bit of bias) we believe that Paragon is one of the best solutions for building RAG & AI applications. Paragon has helped our AI customers scale the number of integrations quickly and reliably across a number of use cases.
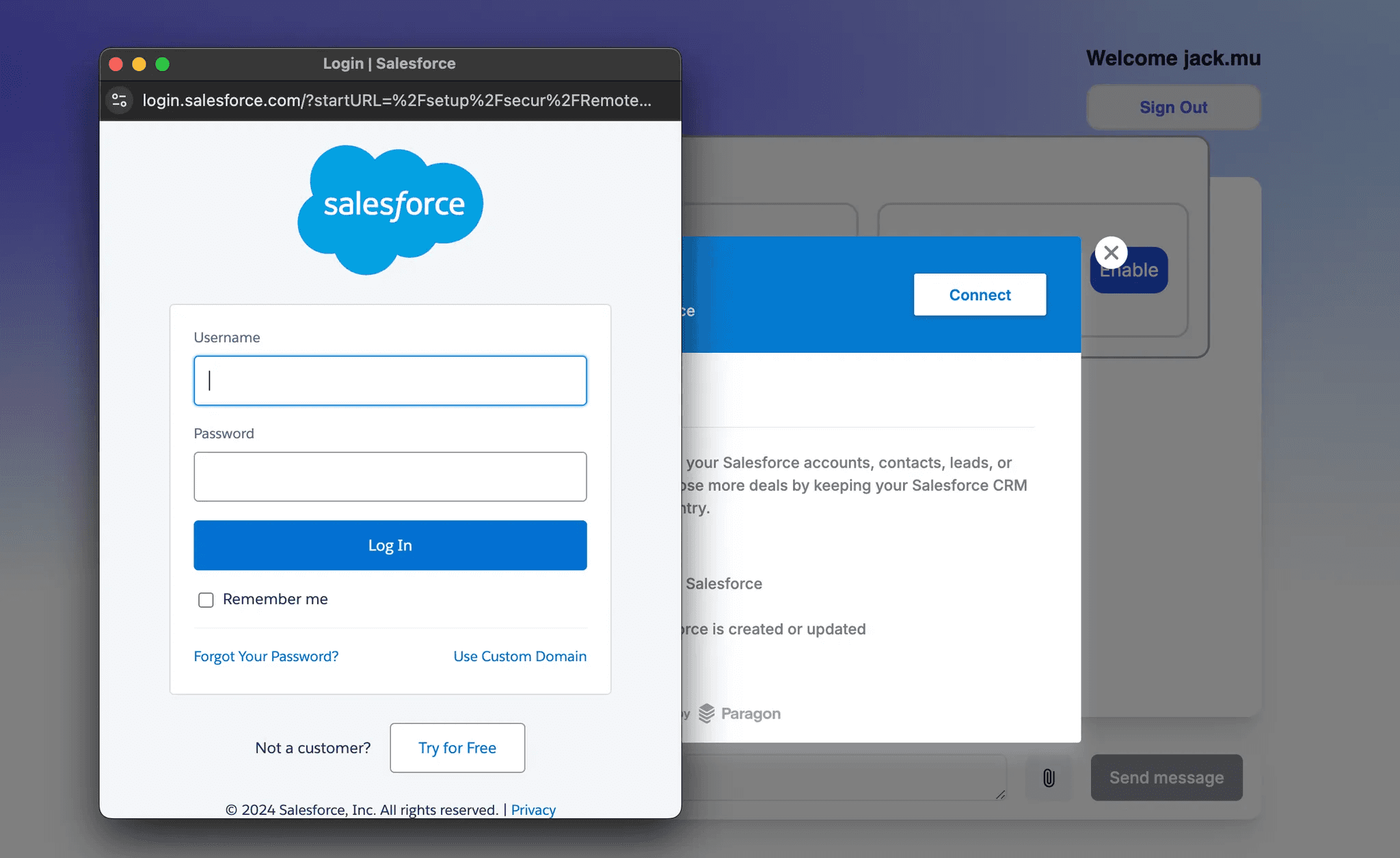
Paragon offers headless as well as pre-built UI components that is embedded right in your application so your users can authenticate into their 3rd-party account. Your users should not even know Paragon exists as everything is embedded in your SaaS application.
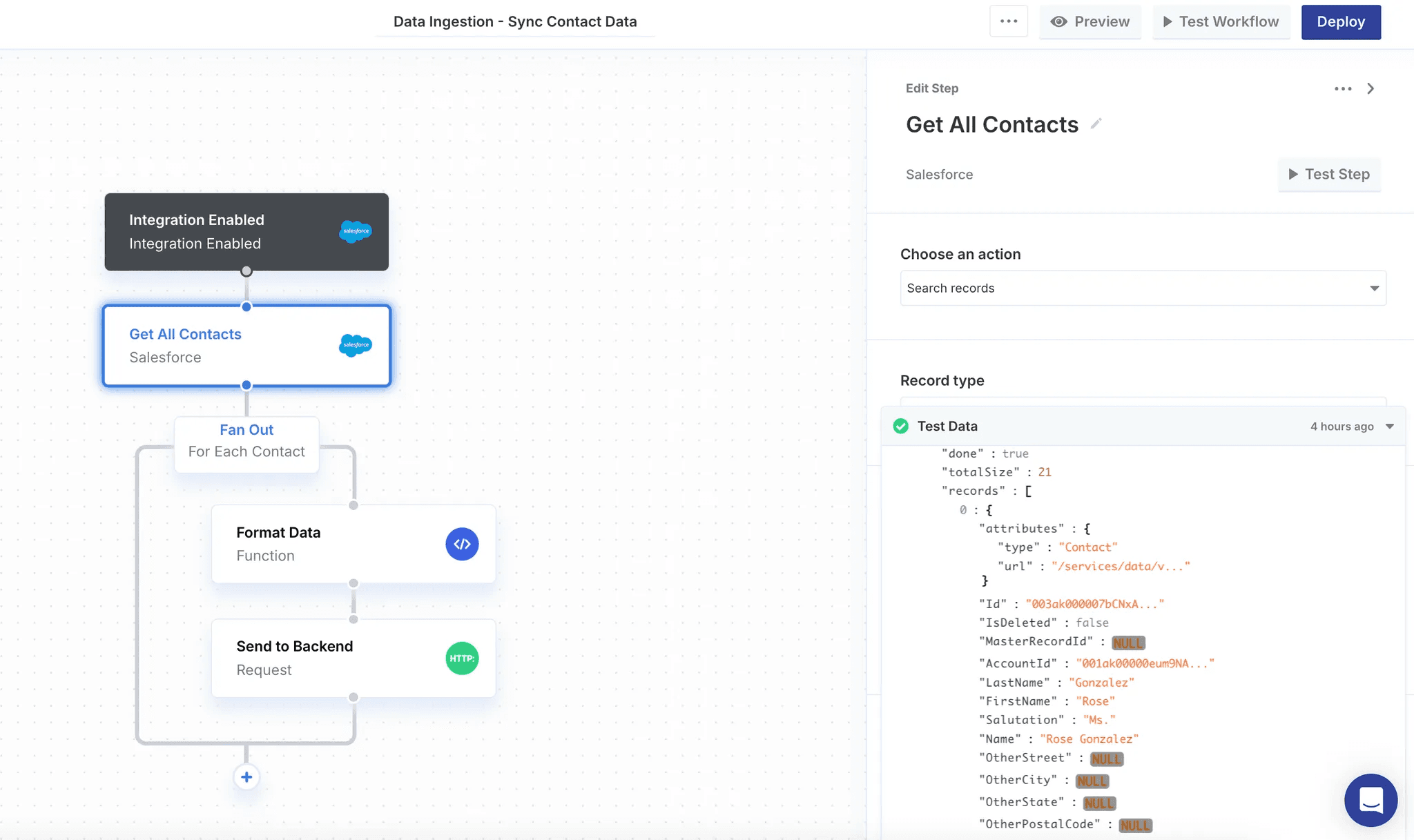
On the backend, Paragon’s workflow engine sits between your application backend and the 3rd-party API. Paragon has managed actions - like “Get All Contacts” in the Salesforce example - that makes extracting data from your users’ 3rd-party platforms an easier process.
Our recommendations for optimization and production
When evaluating tools for production, we recommend:
OpenLLMetry for flexible integration with existing monitoring tools
LLMGuard as a starting point for protecting against prompt injection and jailbreaks
Okta FGA for a flexible authorization model when working with data from different 3rd-party providers
Uptrain for testing and evaluation as it’s open source, provides response metrics and security metrics, and lastly provides an easy-to-set-up dashboard that’s self-hosted (not as a service!)
Paragon for building native integration/connectors into your SaaS application and ingesting data from your users' 3rd-party APIs to your app backend
Wrapping Up
That was a LOT to get through, and we hope this guide helps your team make a more informed decision on technology choices for your RAG application. The team at Paragon has worked with many AI customers with different use cases. If you have any questions or would like to learn more about building native integrations to extract 3rd-party data, read about the topic more in our tutorial series, schedule a call with us, or book a demo.




