

Knowledge AI Chatbot
Building a Permissions System For Your RAG Application
If you're building a RAG application, chances are not all users in a given customer's organization should have access to all indexed data. Adhering to the permissions of the data source application can be tricky, so we put together this tutorial to show you how it can be done.

RAG (Retrieval Augmented Generation) enabled AI applications are enabling chatbots and AI assistants to be increasingly useful, bringing your customers’ data (both internal and from third parties) to LLM’s trained on general knowledge. The simplest form of this is a RAG application that can ingest all your customers’ data into a vector database for prompt retrieval. However, without a permission system, any user - say an intern - could have access to sensitive information such as meeting notes from a private leadership meeting. The ability to incorporate permissions to your RAG enabled application can be the determining factor for turning MVP’s and POC’s to compliant applications your customers can rely on.
Tutorial Overview
In our last tutorial, we built Parato - a RAG enabled chatbot that ingests data from multiple integrations (Google Drive, Slack, and Notion).
In this tutorial, we will walk through how we upgraded Parato to be permission-sensitive. Users will still be able to have their data accessible for Parato to use as context - this context is only given if the authenticated user has access to the source documents. That means if your customer’s marketing team is using your Parato-like chatbot, the chatbot’s answers will only be using data the marketing team has access to. The example below shows the same question - on the right is an authenticated user with permissions to files in Google Drive; on the left, an unauthenticated user (no file permissions).
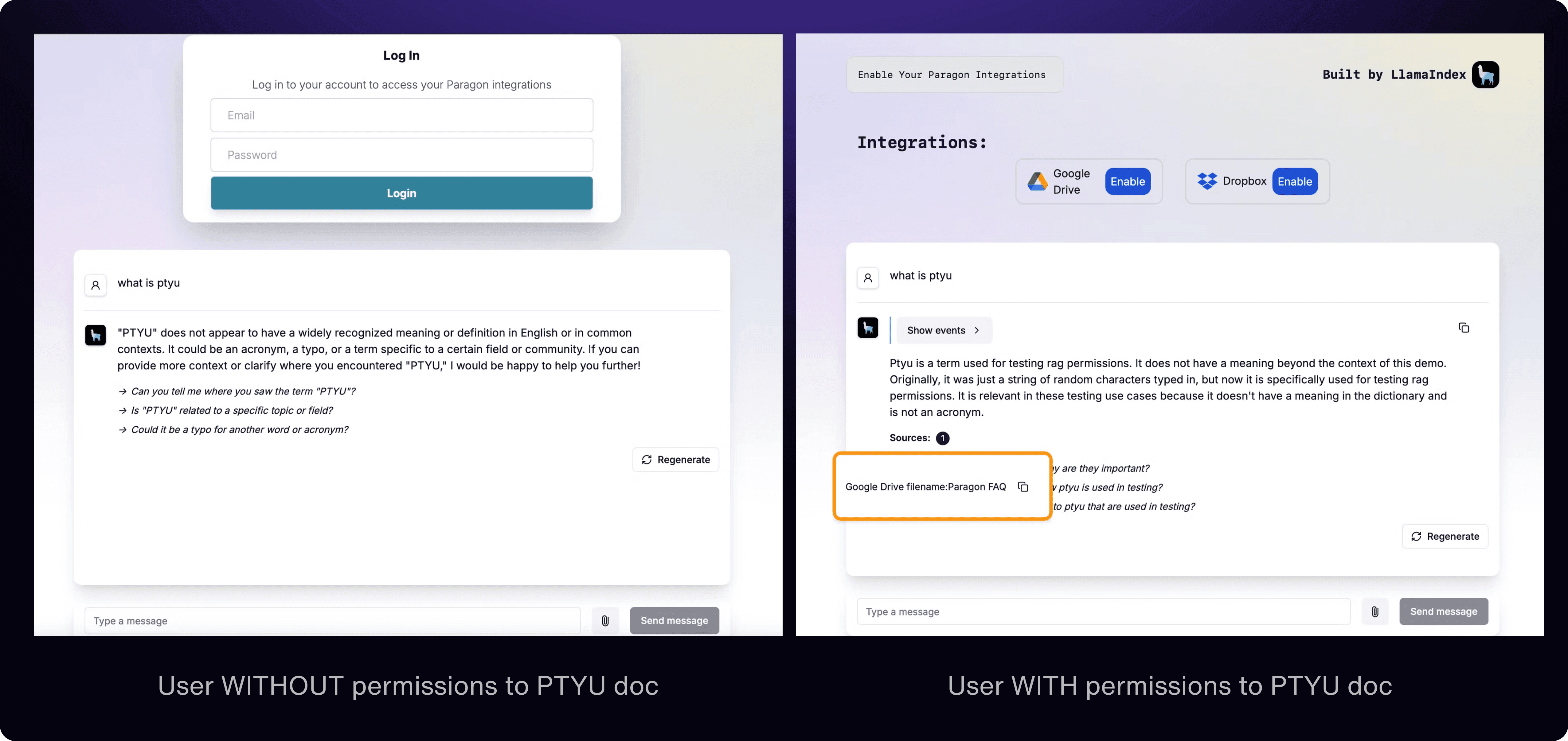
We will also walk through how we are updating permissions in real-time when users or teams are added or removed as contributors/viewers of a file, ensuring Pareto’s policies are changed when permissions are updated.
Watch the video tutorial where we walk through the entire implementation for Parato and our permissions system.
Brief overview of challenges with permissions in RAG
I wanted to provide some context on the challenges of permissions because it will be useful in understanding the design decisions made in this tutorial.
The permissions challenge for RAG enablement across multiple integrated data sources can be broken down into two components:
General permission challenges for a RAG application
Permission challenges when ingesting data from multiple integrations.
Permissions challenges for a RAG application
In many RAG applications, data from third party integrations like Google Drive and Dropbox are transformed and moved to a vector database. When this is the case access control needs to be enforced on vectors in the database. The first step is to decide on an access control system that suits our external data and existing users. This could be RBAC, ABAC, ACL, or ReBAC. Depending on the system, we must also decide on how to filter through permitted documents versus not permitted. This can be done via separate database partitions, metadata filtering, or backend application logic.
Permissions challenges working with data from multiple integrations
Different third party integrations means data with different authorization systems. Google Drive may have one pattern for permissions, while Dropbox may have another. Our two options are to manage our own authorization system, where we keep a record of truth for all of our integrations and reference this system whenever our chatbot application responds, or to have 3rd party checks where we call the 3rd party API to check whether documents returned by our chatbot are permitted at every response call.
For a more high-level overview on the challenges of permissions for RAG, please check out this article.
Permissions architecture
At the time of writing, there is not a standard practice that is used for RAG enablement across multiple integrated data sources. The solution we will walk through aims to address the challenges above while staying true to Parato’s requirements. These requirements are:
Prioritize permissions above all else. Parato has zero margin of error when it comes to returning context from documents a user doesn’t have access to
Given the prioritization of permissions, reduce latency and user wait time as much as possible
Be able to produce a permissions system that can handle multiple integrations, namely Google Drive and Dropbox as these are two popular cloud file storage systems
Setup an extensible platform that can handle even more integrations
Architecture design decisions
The design decisions for Parato starts with the access control method. We are using ReBAC (Relationship Based Access Control) as it can extend to different integrations and their permissions structure. ReBAC uses “relationships” and different “object” types that we can define in our schema. For example, we can model both users having an “owner” relationship to a document, and also a folder having a “parent” relationship with a “document.
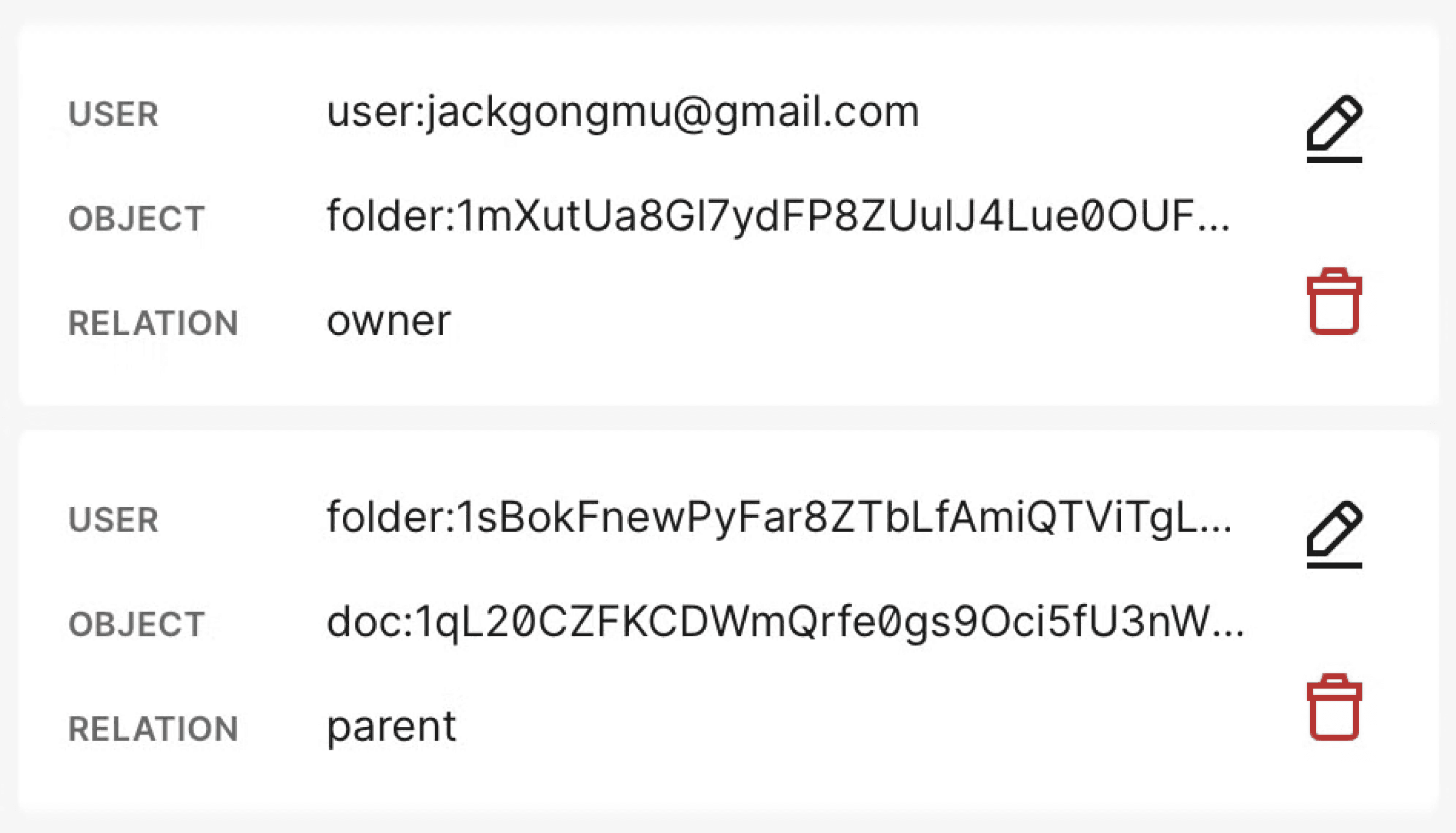
For more information on ReBAC, OpenFGA is a great resource: https://openfga.dev
The next design decision we made is to use both a self-managed authorization system using Okta’s implementation of ReBAC (https://docs.fga.dev) and third party checking. This allows us to be absolutely certain that permissions are correct by going to the source (using Permissions API’s from our third party integrations like Google Drive), while filtering out documents that our self-managed authorization system is confident is not permitted.
Lastly, we also decided on using metadata filtering as well as an in-memory backend process to reconcile retrieved documents with permitted documents. Metadata filtering is supported by many vector database providers like like Pinecone and Apache Solr, allowing us to use the database concurrency to filter documents. The in-memory backend process is the overall process of querying from our Okta Graph Database, calling third party API checks, and querying from Pinecone with metadata filtering.
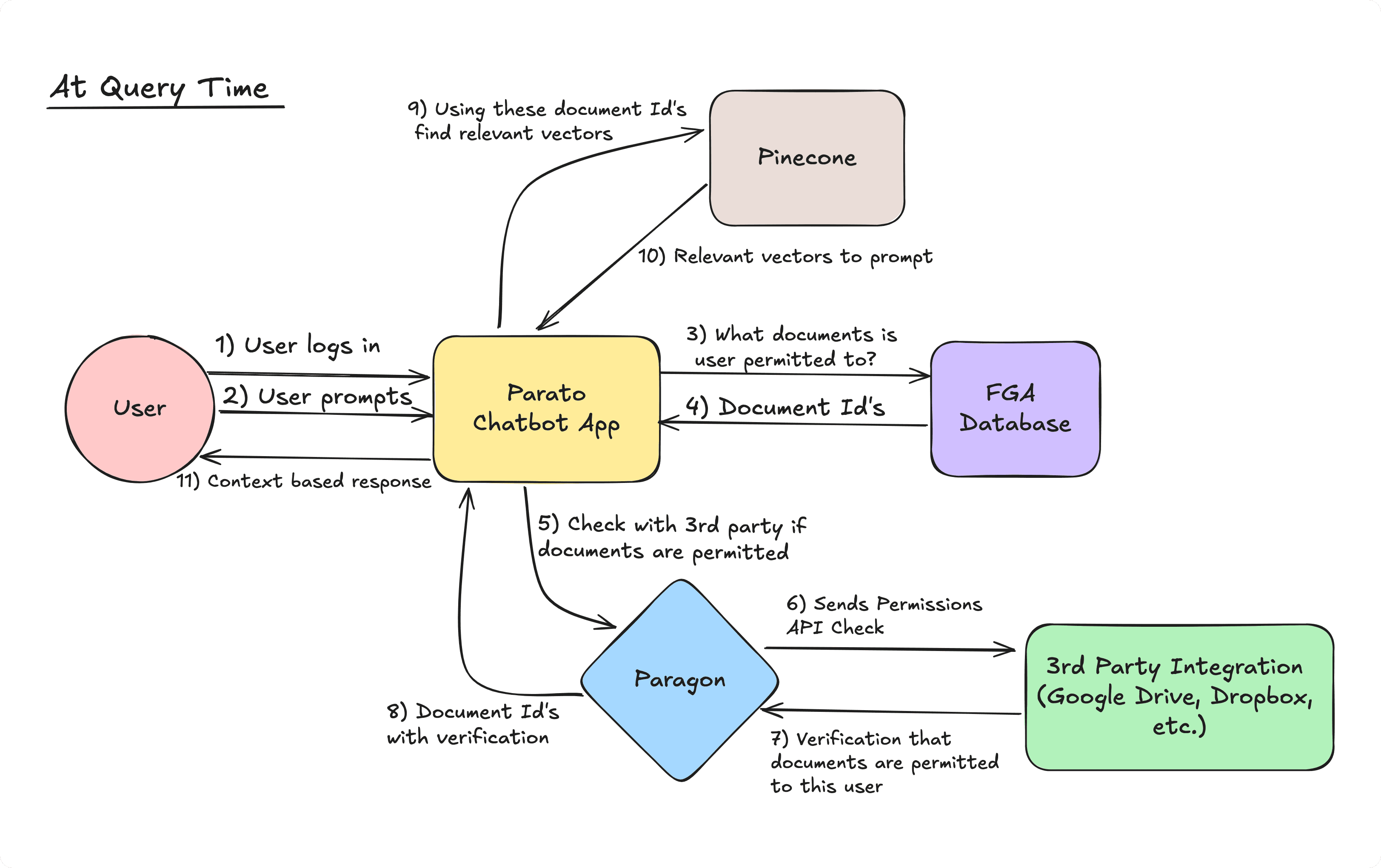
Building Parato’s Permissions Capabilities
Fine Grained Authorization (FGA): Our internal source of truth
To build out our robust permissions system, we start with our ReBAC authorization model. FGA is Okta’s authorization model using a graph database to map relationships. As mentioned earlier, this graph database is our system’s internal source of truth, acting like a cache for permissions before going to the 3rd party check.
FGA isn’t an out-of-the-box solution that will immediately solve for all authorization use cases. The schema definition needs to be general enough to fit different integrations but also specific enough to model relationships usefully.
This schema is general enough for most file storage integrations but if this schema needed to extend to an integration like Slack, more object and relationship types may be needed.
With our FGA graph database set up, Parato’s backend can receive permissions data from third party API’s and write them to the FGA database programatically.
Pinecone metadata: the key to efficient filtering
If you followed along in the first Parato tutorial, Pinecone should be familiar to you as a vector database solution for RAG. The nuance with permissions is that we built our data pipelines to make sure the document Id is kept as metadata. The document Id can come from the third party such as a Google Doc Id, but this Id must be consistent across the FGA Graph and the Pinecone metadata.
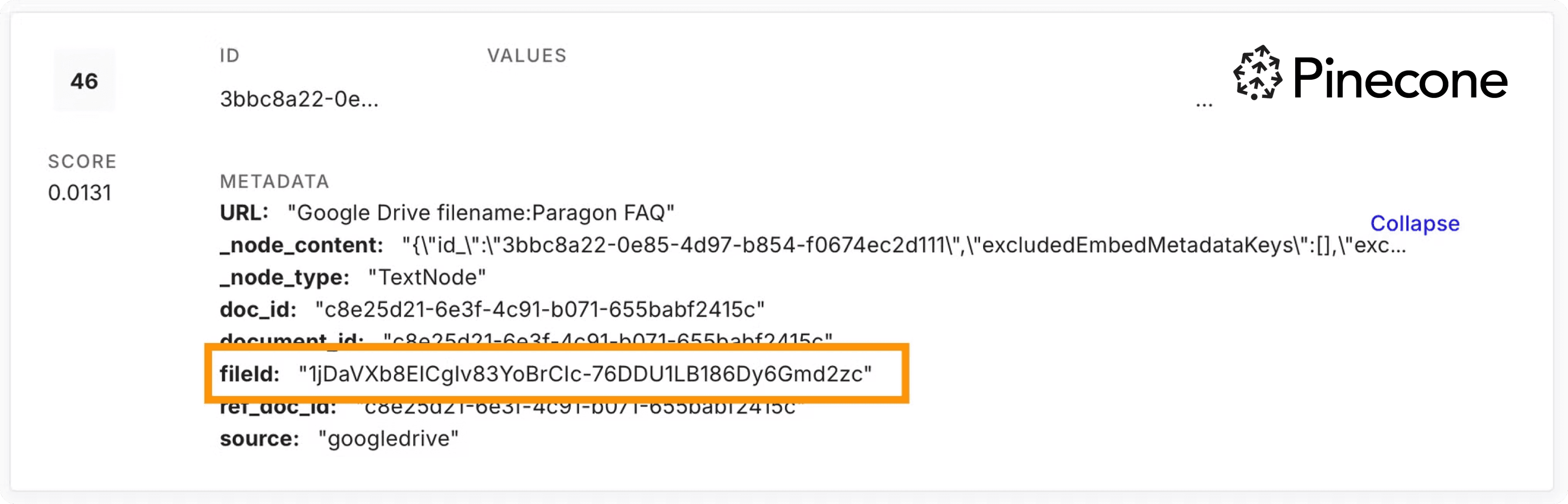
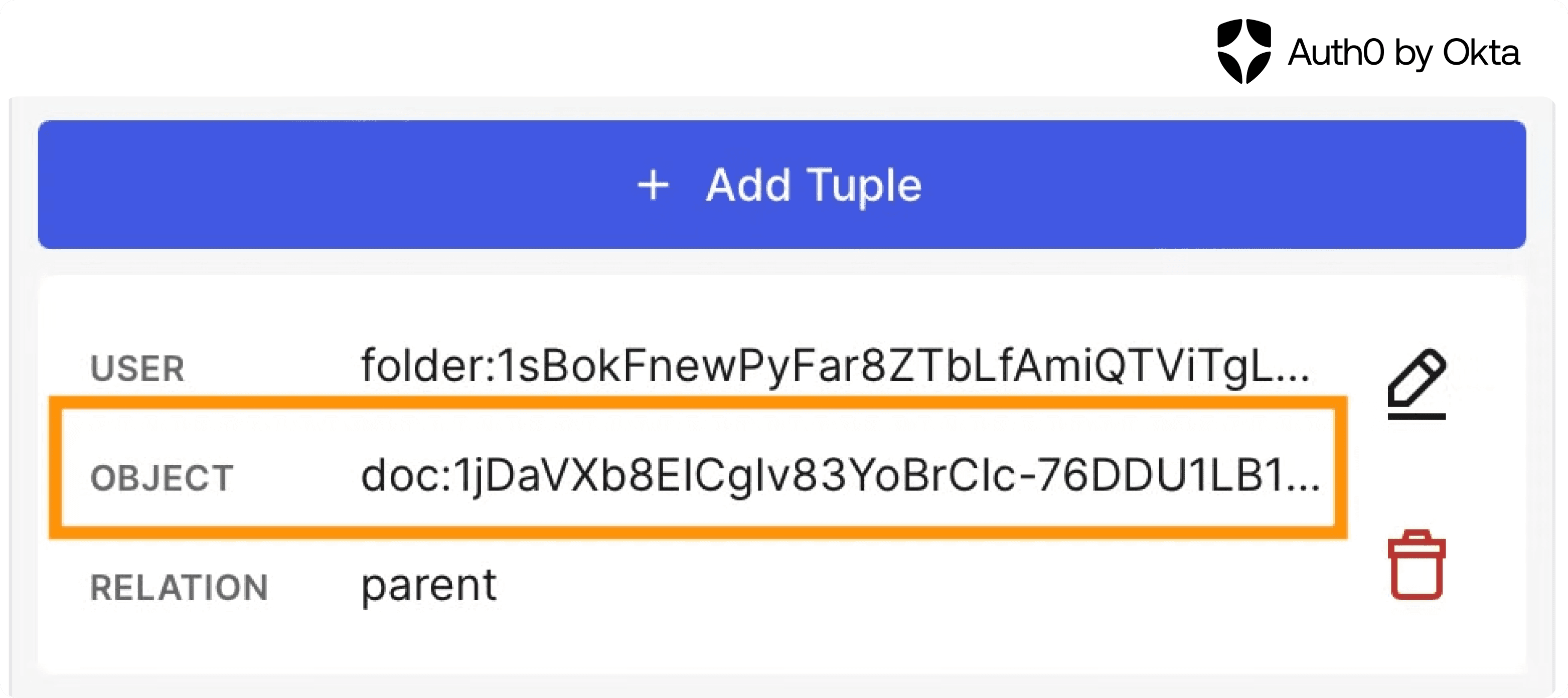
In this example, the “fileId” field in Pinecone matches to the “doc” field in our FGA Graph, ensuring that we can filter on that Id field at retrieval time. Parato’s backend application uses the verified document Id’s to filter vectors with those Id’s in their metadata. This ensures only permitted vector chunks are returned.
Paragon: Parato’s bridge to 3rd-party permissions
Now that we’ve set up our authorization system and our vector database to be equipped with usable metadata, Paragon’s workflow and webhook engine enable us to hydrate these systems with the permissions data they need.
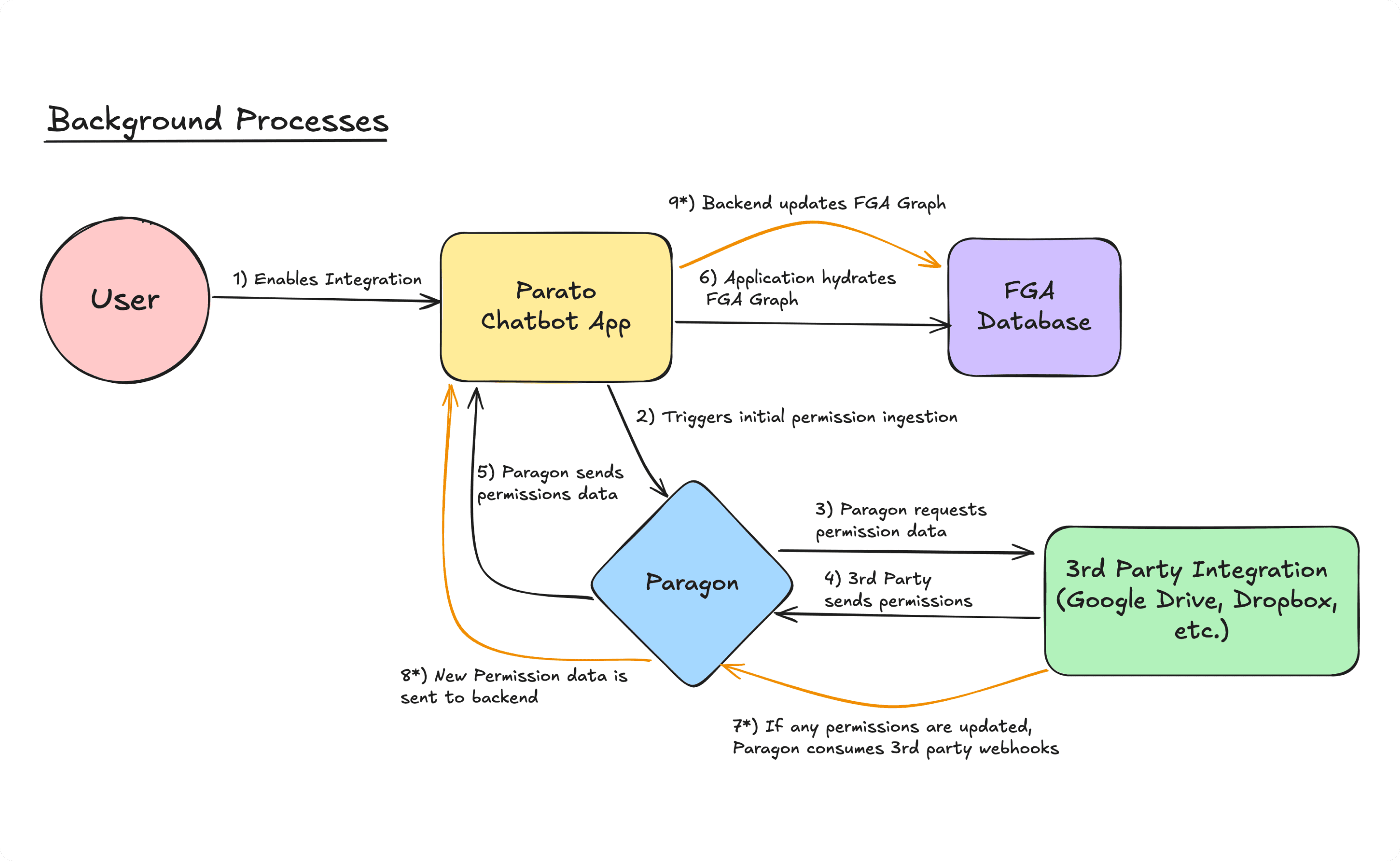
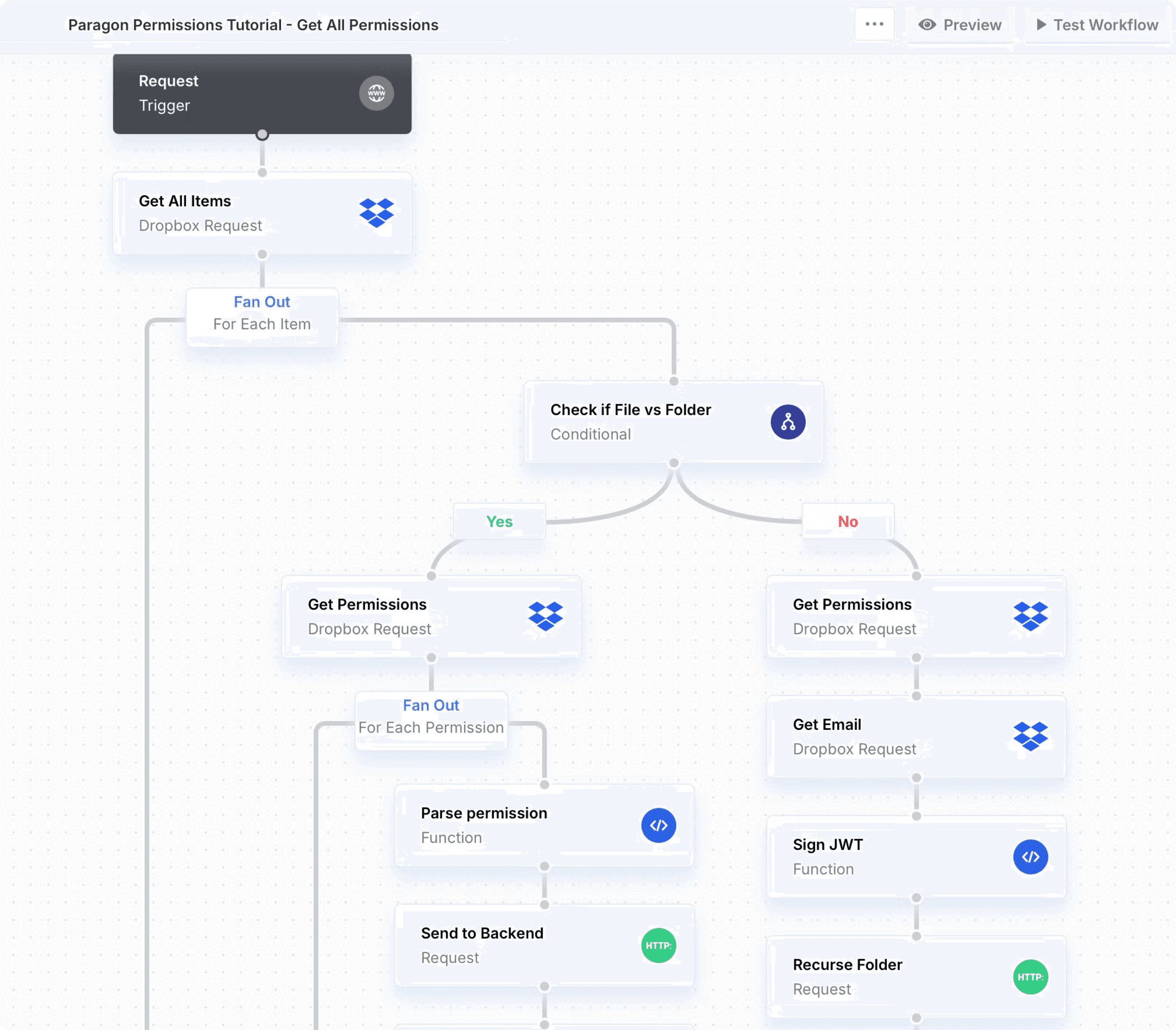
This workflow is part of the initial permission ingestion step (steps 2-5). In the example, Paragon’s workflow engine goes through each item (file and folder), gets its permissions from the Dropbox API, and passes those permissions to Parato’s backend. Dropbox has great documentation (https://www.dropbox.com/developers/documentation/http/documentation) and if interested, we took advantage of the sharing/get_file_metadata endpoint.
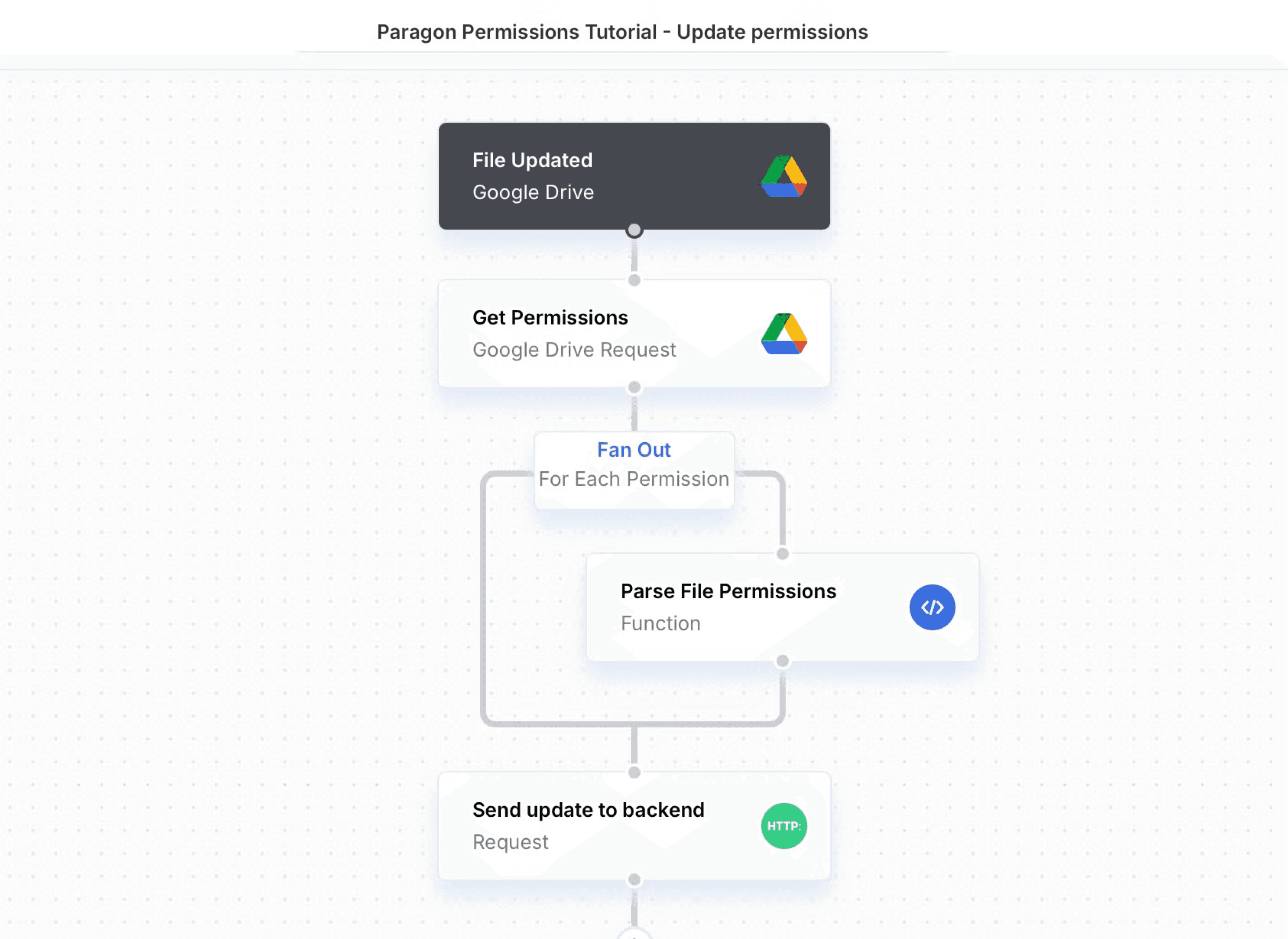
Referencing our requirements for Parato, remember that permissions is the requirement we cannot compromise on. Thus, we not only need to ingest initial permissions properly but when these permissions change, we need webhooks that listen for permission changes and update our authorization system (steps 7-8). Paragon’s webhook engine spins up webhook consumers at scale for us, does some parsing to format the data according to our backend, and sends a POST request with the fresh permission.
We did need to build out some custom logic for Parato to update our authorization graph. It’s interesting to note that Okta’s FGA does not have a tuple update feature, as relationship tuples do not seem to be indexed.
In this snippet, we can see that Parato needs to compare the current users of a role (like writer or viewer) and compare it with the new permissions. New permissions need to have tuples written in our FGA graph; revoked permissions must have those relationship tuples deleted.
Parato’s backend: thoroughness above all else
Many snippets of Parato’s logic have already been showcased thus far. One last feature this tutorial will cover is the verification step of the permissions checking process - the third-party check. Although we try to make our authorization graph reflect the real permissions of our third-party integrations, like any software, there will be errors and faults in the system. To ensure the impact of these faults are mitigated, Parato checks with the actual third-party API before querying Pinecone’s vector database.
For each integration, we hit their API to make sure the document Id’s are permitted using their native authorization.
Additional considerations
This tutorial laid out a fairly exhaustive roadmap for RAG enabled LLM’s with permissions across different integrations. The design decisions we made were guided by Parato’s requirements which required hybrid approaches of self-managed authorization graphs, 3rd party checking, metadata filtering, and others. That being said, your SaaS application will have different requirements and your team can choose to pick parts from this tutorial as inspiration and extend far beyond.
Some additional considerations not implemented in this tutorial, but our team considered:
Identity unification - in our tutorial, Google Drive and Dropbox both use email as a common identifier; some integrations will not have a common identifier like email and so identities will need to be mapped across integrations
Schema for non-file storage integrations - for integrations that have vastly different relationships than file storage, ontology/schema for the graph will need to be modified
Graph database management - Like any database, data retention and clean up will need to be considered (for example, we should delete permission nodes when documents are deleted in Google Drive)
Process differences - your SaaS application may not need all of these checks, caches, and steps. In addition, it may be in your application’s interest to reorder the steps (for example, retrieve relevant vectors and then check their permissions)
We considered this approach but fell back on our current approach as the LlamaIndex abstraction we used doesn’t directly use vectors as inputs; instead they use a vector database retriever as an input to their chat abstraction
One immediate optimization, we had in mind is reducing latency and network calls by cutting out the third party API checks, and only using our FGA database for permissions checking
The third-party check is a redundant check if our FGA graph is correct, and we can lower the probability of errors in our graph database by implementing retries for failed API calls, additional polling for missed messages, and other reconciliation methods
Wrapping up: Parato’s principle
If you made it this far, it should be evident that incorporating third-party permissions to your RAG enabled chatbot is no easy task. Tools like Okta FGA and Paragon lessen the burden for your engineering and product team, and help get your application to a state where data and permissions are ingested and reflected in real time.
Pareto - Parato’s namesake - is an economist who established Pareto’s Principle, also known as the 80/20 rule. (For those that don’t know, this rule states that 80% of the results come from just 20% of the causes; i.e. the top 20% of your highest-spending customers may attribute to 80% of your revenue.)
“Setting up an initial RAG engine can get you 80% of what you hope the feature will do. But permissions is such an important factor for building trustworthy applications, the extra work to build it with consideration, to build it properly is well worth it” -Parato
CHAPTERS
TABLE OF CONTENTS

Jack Mu
,
Developer Advocate
mins to read

