

Integration Guides
Guide: Ingesting Google Drive data for RAG
All the considerations to think about when building RAG data ingestion pipelines from your users’ Google Drive
If you’re looking to build ingestion pipelines from your users’ Google Drive data to your RAG application, this article will cover the following key components:
User setup
File data extraction
Permissions handling
Indexing strategies
Our team at Paragon has helped many AI companies like AI21, Pryon, and Ema build their Google Drive RAG ingestion pipelines. Here’s everything you need to know to avoid common mistakes and build production-ready Google Drive RAG pipelines.
1) User Setup
User OAuth
The first step is setting up a 3rd-party app in the Google Developer Console. This is necessary for your application to send requests to the Google Drive API. After setting up the correct client IDs, secrets, and redirects from the Developer Console (this guide from Google can walk you through the process), your application can initiate the Google OAuth process from within your app. This allows your users to authenticate their Google Drive account directly within your application.
After your user authenticates, you will be returned an access code which you can use to request access tokens and refresh tokens. In your multi-tenant application, you’ll need to keep track of tokens per user, always making sure tokens are fresh so that your users don’t need to constantly re-authenticate. For Google Drive:
Access token expiration = 1 hour
Refresh token expiration = 6 months if unused
there are a few other expiration conditions such as if a user revokes access or changes their password
User Configuration
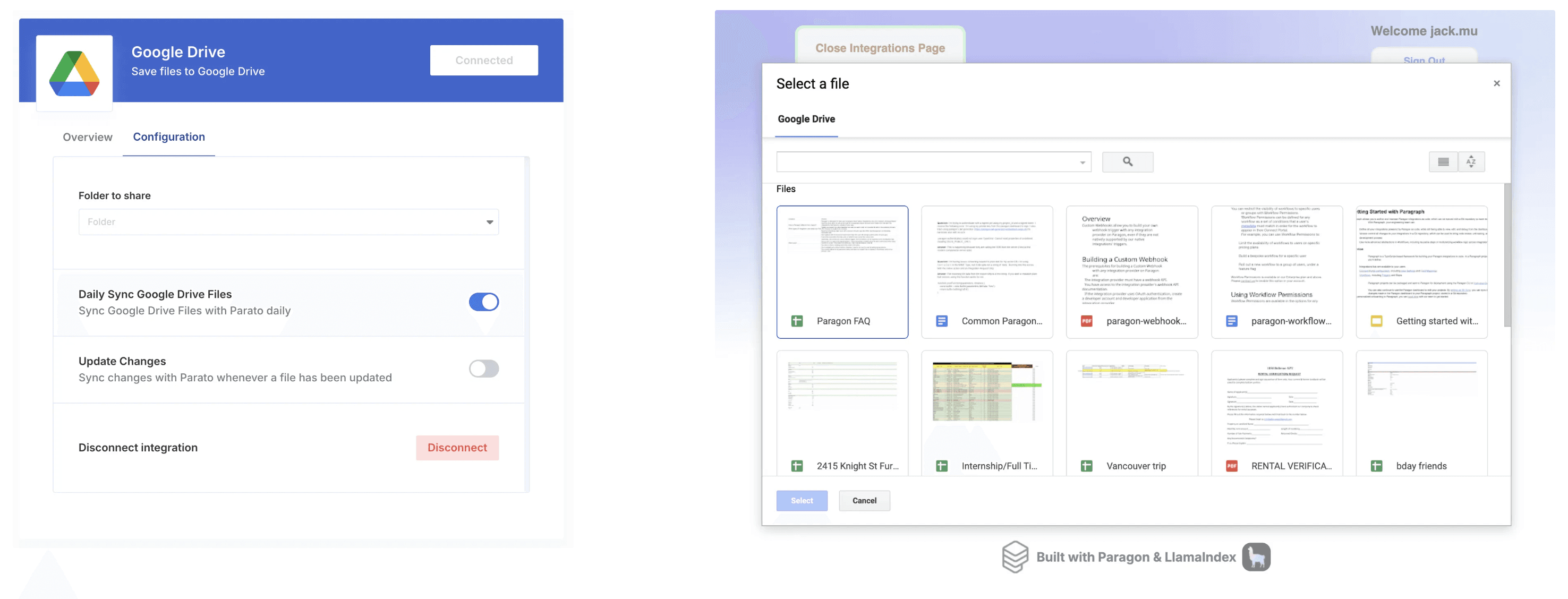
With authentication taken care of, you can now access your customers’ Google Drive files via their API. However, it’s useful (and many times necessary) to allow your users to configure their integration experience. User configurations can include:
Folder pickers that allow users to select folders your AI application to access
File pickers that allow users to select specific files to ingest
Sync frequency: if your user would like your AI application to listen to all changes via webhooks, or if your user would like to have cadenced data syncs instead.
Here’s an example of Paragon’s Connect Portal and a Google Drive filepicker, both embedded UI components that Paragon provides to allow your end user to configure their Google Drive integration.
2) File data extraction
Durable Architecture
While it’s fairly easy to setup a POC where you extract data from tens of hundreds of files, production-ready multi-tenant implementations will require durable architecture design for enterprise scale. Your business customers will have tens of hundreds of employees, each with hundreds of files. When your customers’ admin authenticates their organization’s Google Drive, the scale of files will most likely require a horizontally distributed architecture with multiple workers and queues to ensure that failures are tolerated, retried, and kept track of.
This is a simple architecture of what your services could potentially look like.

Getting All Files
Before processing your users’ Google Drive data, we must first get all of the files a user has given access to. In the User Configuration section, we mentioned that access can be given to an entire Drive, a specific folder, or just specific files.
To access all files in a user’s Drive, the GET <https://www.googleapis.com/drive/v3/files> will return all files by default. For this use case, be sure to use the nextPageToken to recurse through all pages.
To access files in a specific folder, you can use the same GET <https://www.googleapis.com/drive/v3/files> endpoint with the additional query parameter ?q="folder-id"+in+parents to ensure the files are a child of that folder. Again be sure to use the nextPageToken to get all files.
Lastly, to access specific files, Google Drive’s native filepicker returns an array of selected file IDs by default, which you can access in the callback function.
The following is an example of using the native Google Drive filepicker to access a picked file ID.
File Handling
Once you have gotten all user permitted files according to their configurations, you can imagine that there are many different types of files in a users’ Google Drive. Your file processing services need to be able to handle these different types of files. Luckily, there are a few Google Drive APIs that will come in handy.
GET <https://www.googleapis.com/drive/v3/files/{fileId}/export?mimeType={requested_mimetype}>
The export endpoint is useful to export Google-native files - Google Docs, Slides, and Sheets - into requested mime types like text/plain for Docs and text/csv for Sheets.
GET <https://www.googleapis.com/drive/v3/files/{fileId}/?alt=media>
The files endpoint with alt=media is how to download file contents from files that are not Google native - think PDFs, CSVs, DOCs files. The blob file data is returned in hex encoding, which you can then convert to text (this is not well documented, and took us a while to figure out!).
Ingestion Cadence - Current State and State Changes
After we know “how” to extract file data, the next question is “when” to extract file data. It’s logical to get your users’ file data when they first authenticate to their Google Drive - getting the current state of their Google Drive.
Of course, file data isn’t static, and when your users’ create new files, edit files, and delete files, it’s important think about how and when to handle these state changes.
There are two main ways to handle these file changes:
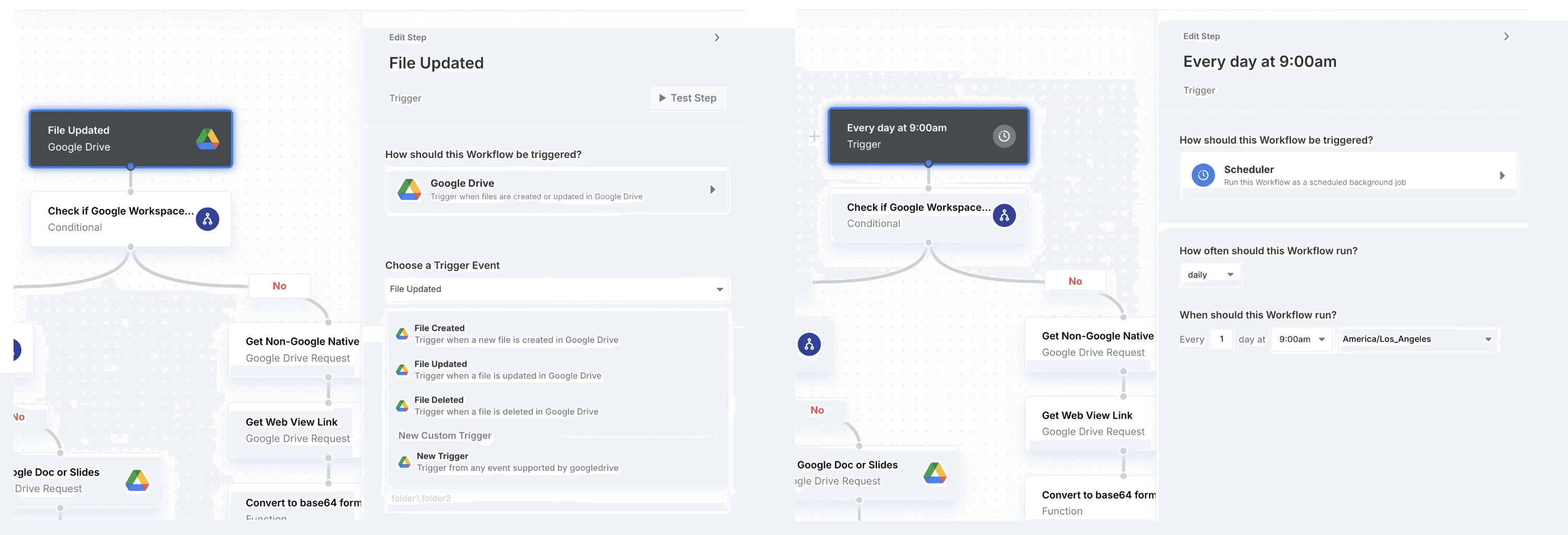
Google Drive webhooks: listen for
file created,file updated, andfile deletedevents, and re-index your database when these events occur.Cadenced syncs: scheduled synchronizations where you can poll for file changes according to a specified cadence - weekly, daily, hourly, etc.
Paragon Workflows are how our customer can build either webhook-driven or cadenced data syncs for Google Drive data, pictured below.
Webhooks are how you can enable a “near real-time” experience where whenever a user changes a file, your application will be able to be up-to-date with those changes quickly. Building a webhook listening architecture however, can come with its own challenges especially when handling multiple tenants. Webhooks have different authentication patterns, requires additional infrastructure, and other considerations to think about (which we lay out in this article on webhooks).
Cadenced syncs are perfect if you don’t want to deal with webhooks and have some tolerance for lagged data. In this scenario, the user configuration will be important to allow your user to select their cadence and opt-in to that schedule.
3) Permissions Handling
One of the most important things you need to support in your Google Drive integration is permissions enforcement. When retrieving relevant context from your vector database (filled with your customers' file data), you must ensure the user querying for that information has read access to the source file in Google Drive. Even if your AI application is incredibly performant, your customers must be able to trust that permissions and data access are handled 100% correctly.
Just imagine if an intern user was able to access their company's sensitive file data like payroll or performance reviews!
Because permissions are so essential to production-ready RAG applications, we put together a hands-on tutorial (with a GitHub repo and workflow templates) if you’d like to put these considerations into practice. In our hands-on tutorial, we built a RAG-enabled chatbot, that ingests Google Drive and Dropbox data, and authorizes RAG retrieval on stored vector chunks based on Google Drive/Dropbox permissions. In our tutorial demo, “PTYU” is a term that we defined in a specific Google Drive file, where only authenticated and authorized users with Google Drive permissions can RAG retrieve that data in a chat interaction.

The permissions considerations below are to model and enforce permissions for your customers’ organization, assuming your customers are ingesting all Google Drive data at an organization level. If you are ingesting Google Drive data at a user level, where your RAG application’s knowledge base is restricted to individual users (as a user, you only have access to files in your own Google Drive), then you can consider keeping each user’s data in their own vector database namespace.
If however, you want users to have RAG-enabled AI applications with full knowledge of all files in your customers’ organization, rather than limiting your application’s knowledge base to one user at a time and storing multiple duplicates of shared files, the following considerations are necessary.
Permissions Extraction
Similar to file extraction, durable architecture and ingestion cadence apply to permissions as well. To avoid too much repeated information, we’ll highlight just a few details.
When building your permissions extraction services, you’ll want to make sure the permissions data is extracted at scale and any errors or unprocessed permissions are monitored. Google Drive permissions will look like this:
And just as file data changes frequently, permissions to a file can be changed as your users add and remove access to files. Use a webhook or cadenced sync pattern to make sure permissions data is up-to-date and your users understand how data and permissions are updated.
Permissions Handling
You may have noticed we left out the “file handling” step in the previous section. This is because permissions handling needs its own dedicated section as there are many details and options to take note of.
Permissions in Google Drive are not just as simple as using
GET <https://www.googleapis.com/drive/v3/files/{fileId}/permissions>
to extract the read, write, and ownership data for each file. File permissions can also be propagated from folder permissions and team permissions.
Permissions to a parent folder can be propagated to child files and child sub-folders.
Permissions can also be propagated from a Google Group where users are part of a group and files/folders are given access to a group rather than explicitly to users.
Another nuance to pay attention to is that Google Drive permissions are not always explicitly given. Users can give permissions by allowing anyone with the file link to view the file.
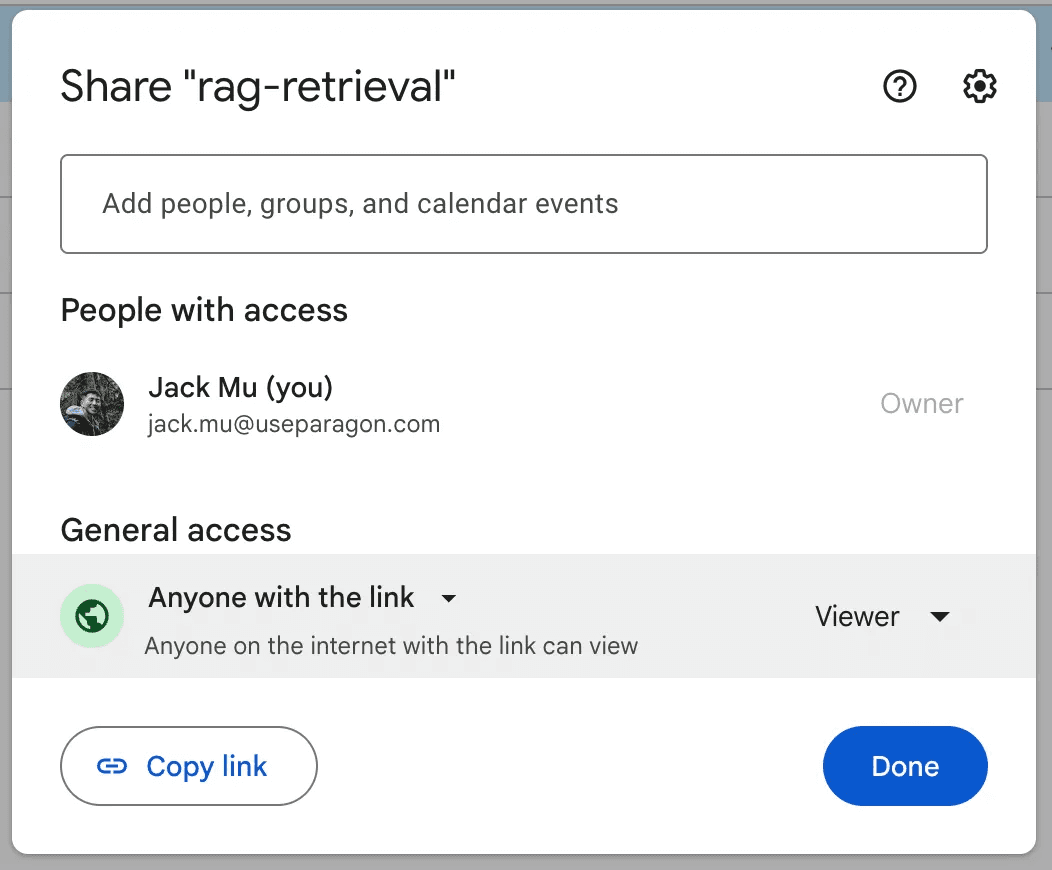
In this case, you will have to use the GET <https://www.googleapis.com/drive/v3/changes>
to track changes in your Google Drive files to properly track permissions.
Permissions Indexing
Whereas file data for RAG is kept in vector databases, permissions data also needs to be indexed for your application to properly authorize data access. There are three main options for indexing permissions:
ReBAC Graph
Because Google Drive permissions behave in a tree/graph structure, many companies choose to model permissions using a “Relationship-based Access Control” (ReBAC) graph. The advantage of using a graph database is modeling Google Drive data similar to how Google Drive natively maps data. A further advantage is the ability to model different 3rd-party permissions like Slack or Salesforce using the same database.
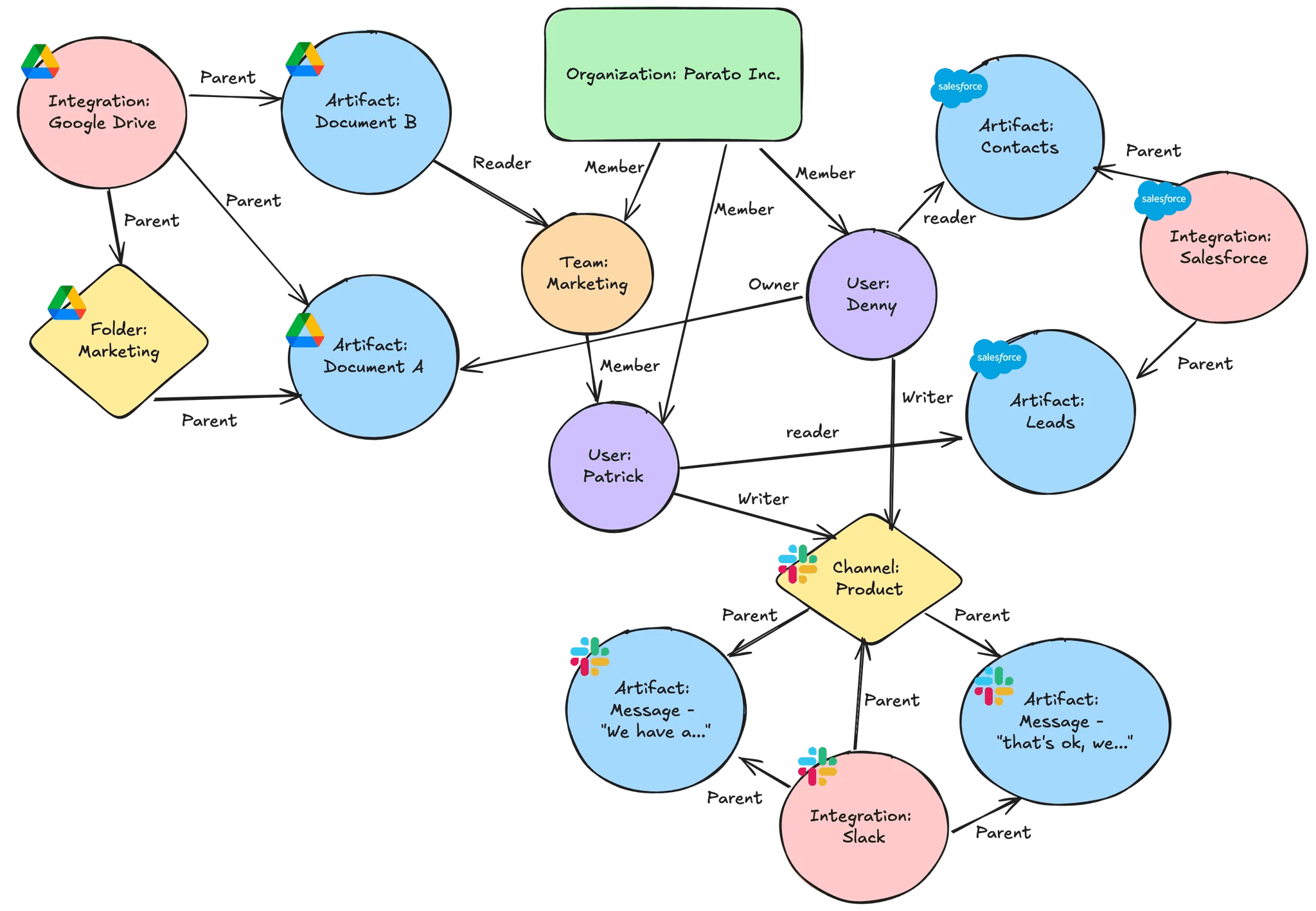
ACL Table
Another method we’ve seen is flattening permissions to an “Access Control List” (ACL) table, where each row in the table is a file with the list of users with access to that file.
Both graphs and ACLs can work in production, but each come with tradeoffs when indexing and updating permissions. For example, updating a ReBAC graph means deleting and creating relationships, as there’s no method to update relationship edges. For ACLs, you can update relationships, however whenever parent permissions are changed (a new member is added to a Group, a permission is changed on a folder), all subsequent files need to have their rows updated. ReBAC graphs handle this much better as only one edge (user to group edge, or user to folder edge) needs to be changed.
At request-time
Checking permissions at request time is choosing to not index permissions in your application - instead you can check permissions at prompt/request time. The advantage to doing this is that your product is not responsible for keeping an up-to-date copy of Google Drive’s permission data, however you would need to check each file’s permissions using the Google Drive API with every AI prompt. This may not be feasible from a latency standpoint if you’re RAG retrieval includes dozens of files to check (if not more).
Permissions Enforcement
However you choose to index permissions, your AI application also needs a strategy for enforcing permissions in your RAG workflow. There are two main ways to do this: pre-retrieval and post-retrieval.
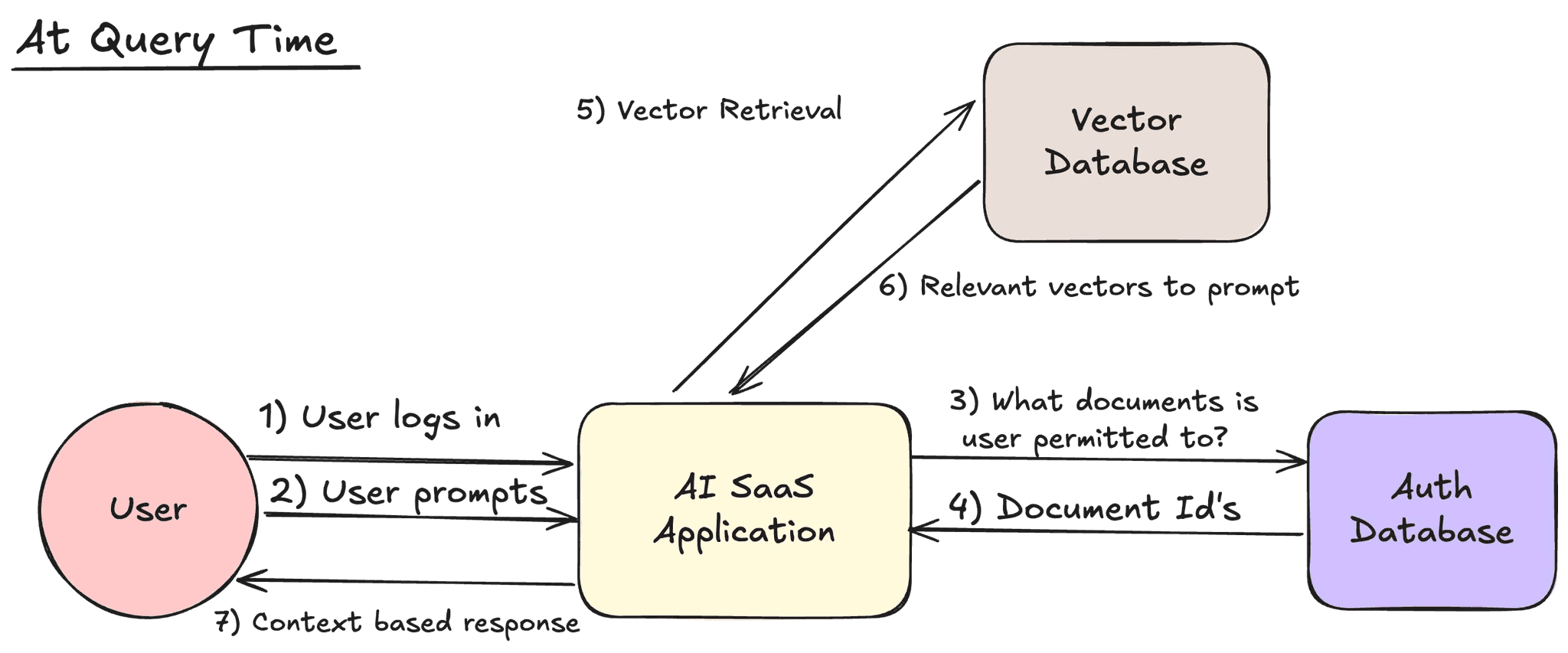
In pre-retrieval, the process would start with using the user’s credentials to get the document IDs of files they have access to (this could be via graph database or ACL). Then using those document IDs, add a filter to the vector database query to only retrieve chunks with those document IDs. The permissions enforcement occurs in step 5, before the vector retrieval.
In post-retrieval, vector retrieval happens first. Then the retrieved chunks with their document IDs are checked against the authorization database (graph or ACL). If your application is checking permissions at request-time (forgoing a permissions database), this is where you would use the Google Drive API to check permissions. The permissions enforcement occurs after step 6, hence post-retrieval.
4) Indexing Strategies
Our last component focuses on indexing to a RAG database. Your product may already have a proprietary process for your RAG pipeline. We would like to just add a few more considerations as Google Drive data can be diverse and Google Drive permissions have come into the fold.
Structured vs Unstructured Data
Similar to how we needed different APIs to handle different file types, we also need different indexing strategies for different file types. For Google Docs, text files, and word files, we can index to a vector database with standard chunk sizes (512 and 1024 token chunks are generally performant) and token overlaps (20 is standard).
For Google Slides and Powerpoint files, chunking by slide is a more appropriate strategy where overlap is not necessary. For structured data like Google Sheets and Excel files, we may not want to chunk at all to keep column headers intact.
Metadata Inclusion
Most vector databases support metadata, included in records as each chunk in a vector database only includes a unique ID, raw text, and its vector representation by default. Metadata is extremely useful for filtering.
One critical use case that requires metadata filtering is permissions enforcement - we keep the Google Drive document ID in metadata that we can use for filtering when enforcing permissions pre-retrieval or checking document IDs post-retrieval.
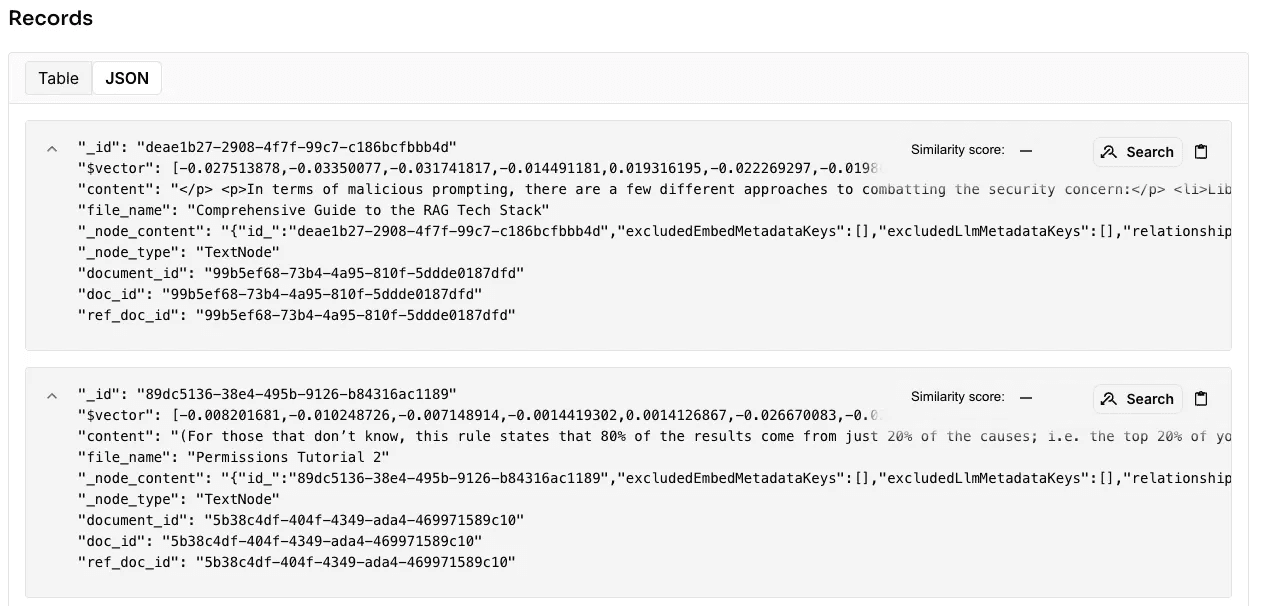
Other types of metadata you may consider including is an update datetime that allows your application to check if file data in the vector database is potentially stale or up-to-date, filenames to source RAG responses, web links to allow users to redirect to the source file, and data sources if you have multiple integrations like Sharepoint or Notion.
Vector Database Namespaces
If you already have a RAG system in place, this will no doubt be obvious. If Google Drive is your first data source, you will want to keep separate namespaces per tenant in your application to ensure each of your customers’ data is kept separate from one another. Namespaces are partitions in a vector database. When you query from a partition, only chunks held in that namespace will be available to retrieve.
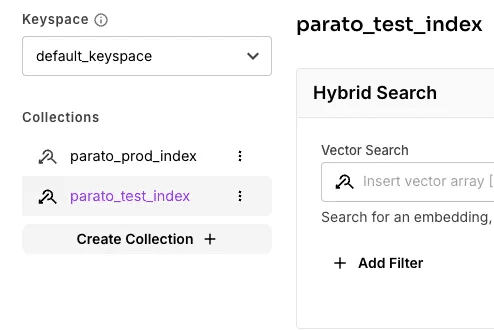
Namespaces are also useful for keeping separate environments, such as your development, test and production environments.
Wrapping Up
That’s a wrap for the key considerations we've had to walk through with our AI customers like AI21, Pryon, Ema, and more. We went over:
How users can setup their Google Drive integration within your application
How to extract Google Drive file data
How to handle Google Drive permissions in a RAG workflow
How to index data for RAG given multiple file types, permissions, and tenants
Designing and building out this Google Drive integration feature will undoubtably take a large effort. Paragon can drastically simplify the process and cut a bulk of the engineering effort required as we’ve helped customers solve for this exact use case and have built purpose-built products that solve these type of AI use cases. If you’re interested in learning how Paragon can help your team ship a Google Drive ingestion integration for RAG 7x faster, book a demo with our team.
TABLE OF CONTENTS

Jack Mu
,
Developer Advocate
mins to read

